Certamente você já se perguntou qual é o site de raspagem. É um processo de uso de bots para extrair conteúdo e dados de um site. Desta forma, o código HTML é extraído. E, com ele, os dados armazenados no banco de dados. Isso significa que você pode duplicar ou copiar todo o conteúdo do site em outro lugar.
O site de raspagem é usado em muitas empresas digitais dedicadas à coleta de bancos de dados. Para esclarecer melhor o que o site de raspagem deve saber quais são os casos de uso legítimo:
- Os robôs dos mecanismos de pesquisa rastreiam um site, analisam seu conteúdo e depois classifique-o.
- sites de comparação de preços que implementam bots para obter automaticamente preços e descrições de produtos para sites de vendedores aliados.
- empresas de pesquisa de mercado que usam para extrair dados de fóruns e redes sociais.
Para ter mais informações sobre o que a web raspagem deve saber que também é usada para fins ilegais. Incluindo raspagem de preços e roubo de conteúdo de direitos autorais. Uma entidade digital afetada pode sofrer sérios perdas financeiras. Especialmente se é uma empresa baseada principalmente em modelos de preços competitivos ou ofertas em distribuição de conteúdo.
Você realmente sabe qual é o site de raspagem?
As ferramentas da Web de raspagem são o software, isto é, bots agendados para examinar bancos de dados e extrair informações. Uma grande variedade de tipos de garrafas é usada, muitos deles totalmente personalizáveis para:
- reconhecem estruturas exclusivas de sites HTML.
- Extrair e transformar conteúdo.
- Armazenar dados.
- Extrair dados da API.
Como todos os bots usam o mesmo sistema para acessar os dados do site, às vezes é difícil distinguir entre bots legítimos e bots maliciosos.
Diferenças-chave entre bots legítimos e maliciosos
Existem algumas diferenças importantes que irão ajudá-lo a distinguir entre os dois:
- Os robôs legítimos são identificados com a organização para a qual eles fazem isso. Por exemplo, o Googlebot é identificado em seu cabeçalho HTTP como pertencente ao Google. Os robôs maliciosos, no verso, são passados através de tráfego legítimo ao criar um usuário HTTP falso.
- Os robôs legítimos respeitam o arquivo robot.txt de um site, que lista as páginas que você pode acessar um robô e esses quem não. O malicioso, por outro lado, acompanhar o site, independentemente do que o operador do site permitiu.
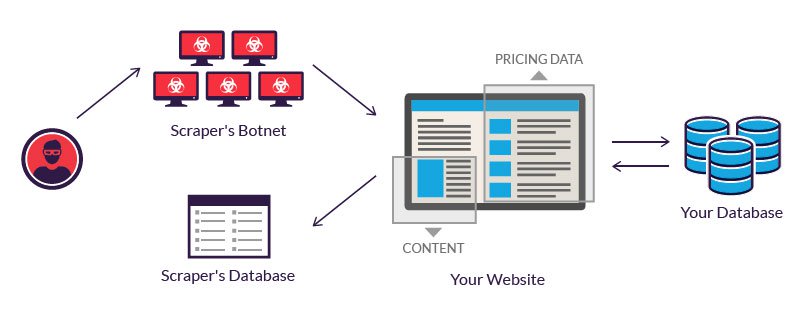
Os bots legítimos de bots investem em servidores para processar a grande quantidade de dados que é extrair. Um atacante, que não tem tal orçamento, muitas vezes resorts ao uso de uma rede de garrafas. Isto é, computadores geograficamente dispersos, infectados com o mesmo malware e controlado de uma localização central.
Os proprietários de bots individuais Os computadores não sabem de sua participação. O poder combinado de sistemas infectados permite raspagem em grande escala de muitos sites diferentes por parte do autor.
Exemplos do que o site de raspagem é

O site de raspagem é considerado malicioso quando os dados são extraídos sem a permissão dos proprietários do site. Os dois casos de uso mais comuns estão raspando os preços e o roubo de conteúdo.
1.- Preços de raspagem
no preço de raspagem é uma das variantes para saber qual é o site de raspagem. É um invasor que geralmente usa uma rede bot a partir da qual lançar os bots de raspagem da Web para inspecionar os bancos de dados da competição. O objetivo é acessar informações de preços, ganhar rivais e impulsionar as vendas. Para atacantes, uma rascunho de preço bem-sucedido pode tornar suas ofertas destacadas em sites de comparação.
Os ataques ocorrem frequentemente nas indústrias onde o preço dos produtos é facilmente comparável. Porque o preço desempenha um papel importante nas decisões de compra. As vítimas de raspagem de preços podem ser agências de viagens, vendedores eletrônicos on-line, etc.
Por exemplo, comerciantes eletrônicos de smartphone, que vendem produtos semelhantes a preços relativamente importantes, são objetivos frequentes. Para permanecer competitivo, eles têm que vender seus produtos com o melhor preço possível.
Como os clientes sempre escolhem a oferta mais econômica.Para obter uma vantagem, um provedor pode usar um bot para raspar continuamente os sites de seus concorrentes e atualizar quase instantaneamente seus próprios preços em conformidade.
2.- Conteúdo de raspagem
O conteúdo de raspagem é Outras formas que nos permite entender o que é o site de raspagem. Isto é, o assalto em larga escala de um determinado site. Objetivos típicos incluem catálogos on-line de produtos e sites baseados no conteúdo digital para aumentar o negócio. Para essas empresas, um ataque de raspagem de conteúdo pode ser devastador.
Por exemplo, diretórios de negócios on-line investem quantidades significativas de tempo, dinheiro e energia na construção de seu banco de dados. O raspagem pode fazer tudo ir para a preocupação. É usado em campanhas de transporte de correio indesejadas. O inverso aos concorrentes. É provável que qualquer um desses fatos afecte os resultados de uma empresa e suas operações diárias.
Proteção contra a Web de raspagem
1.- É importante agir legalmente
A maneira mais fácil de evitar que a raspagem seja uma medida legal. Um em que você pode dizer judicialmente o ataque e no qual você mostra que o raspagem da web não é permitido.
Você pode até processar possíveis raspadores se você explicitamente proibiu em seus termos de serviço. Por exemplo, o LinkedIn processou um conjunto de raspadores no ano passado, dizendo que a extração de dados do usuário por meio de solicitações automatizadas é equivalente à pirataria.
2.- Prevenir ataques de solicitações que chegam
Mesmo se você publicou um aviso legal que proíbe raspando seus serviços, é possível que um atacante em potencial ainda deseja avançar com o processo. Você pode identificar possíveis endereços IP e impedir que solicitações atinjam o seu serviço filtrando através do firewall.
Embora seja um processo manual, os modernos provedores de serviços de nuvem oferecem acesso a ferramentas que bloqueiam possíveis ataques. Por exemplo, se você estiver hospedando seus serviços nos serviços da Web da Amazon, o escudo da AWS ajudaria a proteger seu servidor de possíveis ataques.
3.- Usar solicitações de falsificação de solicitação (CSRF)
quando Usando tokens CSRF em seu aplicativo, você evitará ferramentas automatizadas de fazer solicitações arbitrárias para os URLs convidados. Um token CSRF pode estar presente como um campo de forma oculto.
Para superar um token CSRF, é necessário fazer o upload e analisar a marca e procurar o token correto, antes de agrupá-lo com a solicitação. Esse processo requer habilidades de programação e acesso a ferramentas profissionais.
4.- Use o arquivo .htaccess para evitar raspagem
.htaccess é um arquivo de configuração para o seu servidor da web. E pode ser modificado para impedir que os raspadores acessem seus dados. O primeiro passo é identificar raspadores, que podem ser feitos através do Google Webmasters.
Depois de identificá-los, você pode usar muitas técnicas para parar o processo de raspagem alterando o arquivo de configuração. Em geral, este arquivo não está habilitado pelo que você deve estar habilitado, somente dessa maneira você irá interpretar os arquivos que você colocará em seu diretório.
5.- Impedir hotlinking
Quando arranhou seu conteúdo, os links on-line para imagens e outros arquivos são copiados diretamente no site do invasor. Quando o mesmo conteúdo é exibido no site do invasor, o referido recurso está diretamente vinculado ao seu site.
Este processo de mostrar um recurso hospedado no servidor em um site diferente é chamado de hotlinking. Quando você evita um link ativo, uma imagem desse tipo, quando exibida em um site diferente, ele não é feito através do seu servidor.
6.- Endereços IP específicos das listas negras
Se você identificou endereços IP ou padrões de endereço IP que são usados para raspar, você pode simplesmente bloqueá-los através do seu .htaccess.
7.- Limite o número de solicitações de um endereço IP
como alternativa, você também pode limitar o número de solicitações de um endereço IP. Embora possa não ser útil se um invasor tiver acesso a vários endereços IP. Você também pode usar um caso de solicitações anormais de um endereço IP.
O que você precisa fazer é bloquear o acesso dos endereços IP conhecidos do serviço de acomodação e rastreamento em nuvem para garantir que um invasor não possa Use este serviço para excluir ou copiar seus dados.
8.- Criar “honeypots”
A “honeypot” é um link para o conteúdo falso que é invisível para um usuário normal, mas Está presente no HTML. Parece quando um programa analisa o site.Ao redirecionar um raspador para os ditos honeypots, ele pode detectar raspadores e torná-los recursos de resistência ao visitar páginas que não contenham dados.
Portanto, não se esqueça de desativar esses links no arquivo robots.txt para fazer Certifique-se de que um localizador de mecanismos de pesquisa não termine em tais honeypots.
9.- Alterar a estrutura do HTML com frequência
A maioria dos rastreadores analisa o HTML que é obtido a partir do servidor. Para dificultar o acesso de raspadores a dados, você pode alterar com freqüência a estrutura HTML. Para fazer isso, um invasor deve avaliar novamente a estrutura do seu site para extrair os dados. Outra chave para saber qual é o site de raspagem.
10.- Fornecer APIs
Você pode permitir a extração de dados seletiva do seu site se você definir determinadas regras. Uma maneira é criar APIs com base em assinaturas para monitorar e dar acesso aos seus dados. Através das APIs, você também pode supervisionar e restringir o uso do serviço que você oferece.
Se você não quiser raspando problemas da Web ou complicações de qualquer tipo, você deve sempre confiar em plataformas que lhe dão segurança. E isso também, você oferece os serviços que você precisa para cada campanha de marketing. E na frente você pode ajudá-lo a esse respeito. Confie em nossos serviços de marca & Marketing de conteúdo e você verá como será fácil e eficaz.