Segur que alguna vegada t’has preguntat què és el web scraping. Es tracta d’un procés d’usar bots per extreure contingut i dades d’un lloc web. D’aquesta manera s’extreu el codi HTML. I, amb ell, les dades emmagatzemades a la base de dades. Això suposa que es pot duplicar o copiar tot el contingut del lloc web en un altre lloc.
El web scraping s’utilitza en moltes empreses digitals que es dediquen a la recopilació de bases de dades. Per aclarir millor què és el web scraping has de saber quins són els casos d’ús legítim de la mateixa:
- Els robots dels motors de cerca rastregen un lloc, analitzen el seu contingut i després el classifiquen.
- llocs de comparació de preus que implementen bots per obtenir automàticament preus i descripcions de productes per a llocs web de venedors aliats.
- Companyies d’investigació de mercat que l’utilitzen per extreure dades de fòrums i xarxes socials.
per a tenir més informació sobre què és el web scraping has de saber que també s’utilitza per a fins il·legals. Inclosa el raspat de preus i el robatori de contingut amb drets d’autor. Una entitat digital afectada pot patir greus pèrdues financeres. Especialment si es tracta d’un negoci que es basa fonamentalment en models de preus competitius o ofertes en la distribució de contingut.
Saps realment què és el web scraping?
Les eines de web scraping són programari, és a dir, brossa programats per examinar bases de dades i extreure informació. S’utilitza una gran varietat de tipus de bot, molts d’ells totalment personalitzables per:
- Reconèixer estructures de llocs HTML únics.
- Extreure i transformar continguts.
- Emmagatzemar dades.
- Extreure dades de les API.
Atès que tots els bots utilitzen el mateix sistema per accedir a les dades de el lloc, de vegades pot resultar difícil distingir entre brossa legítims i brossa maliciosos.
diferències clau entre brossa legítims i maliciosos
Hi ha algunes diferències clau que t’ajudaran a distingir entre els dos:
- Els robots legítims s’identifiquen amb l’organització per a la qual ho fan. Per exemple, Googlebot s’identifica en la seva capçalera HTTP com a pertanyent a Google. Els robots maliciosos, al revés, es fan passar per tràfic legítim a l’crear un usuari HTTP fals.
- Els robots legítims respecten l’arxiu robot.txt d’un lloc, que enumera les pàgines a les que pot accedir un robot i les que no. Els maliciosos, per altra banda, rastregen el lloc web independentment del que l’operador de el lloc hagi permès.
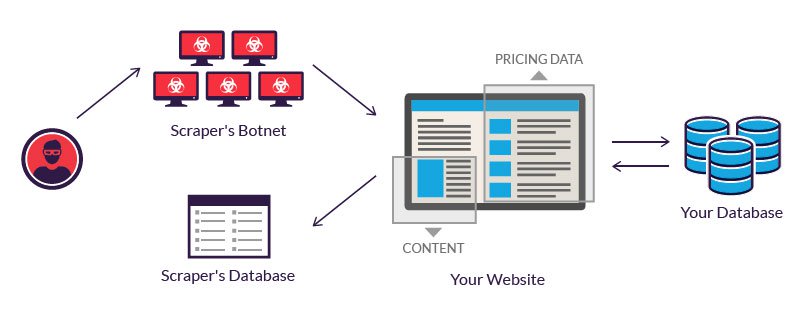
Els operadors legítims de bots inverteixen en servidors per processar la gran quantitat de dades que es extreuen. Un atacant, que no té tal pressupost, sovint recorre a l’ús d’una xarxa de bots. És a dir, ordinadors geogràficament dispersos, infectades amb el mateix malware i controlades des d’una ubicació central.
Els propietaris d’ordinadors de bots individuals desconeixen la seva participació. El poder combinat dels sistemes infectats permet el raspat a gran escala de molts llocs web diferents per part de l’autor.
Exemples de què és l’web scraping

el web scraping es considera maliciós quan les dades s’extreuen sense el permís dels propietaris de llocs web. Els dos casos d’ús més comuns són el raspat de preus i el robatori de contingut.
1.- Raspat de preus
En el raspat de preus és una de les variants per saber què és el web scraping. Es tracta d’un atacant que generalment utilitza una xarxa de bots des de la qual llançar brossa de web scraping per inspeccionar les bases de dades de la competència. L’objectiu és accedir a la informació de preus, guanyar als rivals i impulsar les vendes. Per als atacants, 1 raspat de preus reeixit pot fer que les seves ofertes siguin destacades en llocs web de comparació.
Els atacs ocorren amb freqüència en indústries on el preu dels productes són fàcilment comparables. Perquè el preu juga un paper important en les decisions de compra. Les víctimes de l’raspat de preus poden ser agències de viatges, venedors d’electrònica en línia, etc.
Per exemple, els comerciants electrònics de telèfons intel·ligents, que venen productes similars a preus relativament importants, són objectius freqüents. Per seguir sent competitius, han de vendre els seus productes a el millor preu possible.
Ja que els clients sempre solen optar per l’oferta més econòmica.Per obtenir un avantatge, un proveïdor pot usar un bot per raspar contínuament els llocs web dels seus competidors i actualitzar gairebé instantàniament els seus propis preus en conseqüència.
2.- Raspat de contingut
el raspat de contingut és una altra de les formes que permet comprendre què és el web scraping. És a dir, el robatori de contingut a gran escala d’un lloc determinat. Els objectius típics inclouen catàlegs de productes en línia i llocs web que es basen en contingut digital per impulsar el negoci. Per a aquestes empreses, un atac de raspat de contingut pot ser devastador.
Per exemple, els directoris de negocis en línia inverteixen quantitats significatives de temps, diners i energia en la construcció de la base de dades. El raspat pot fer que tot es vagi a l’orris. S’usa en campanyes d’enviament de correu no desitjat. O es revèn als competidors. És probable que qualsevol d’aquests fets afecti els resultats d’una empresa ja les seves operacions diàries.
Protecció contra el web scraping
1.- és important actuar de forma legal
La forma més fàcil d’evitar el raspat és prendre una mesura legal. Una en la qual puguis denunciar judicialment l’atac i en la qual demostris que el raspat web no està permès.
Fins i tot pots demanar a possibles raspadors si ho has prohibit explícitament en els teus termes de servei. Per exemple, LinkedIn va demandar a un conjunt de raspadors l’any passat, dient que l’extracció de dades d’usuaris a través de sol·licituds automatitzades equival a pirateria.
2.- Prevenir atacs de les sol·licituds que arribin
Fins i tot si has publicat un avís legal que prohibeixi el raspat dels teus serveis, és possible que un atacant potencial encara vulgui seguir endavant amb el procés. Pots identificar possibles adreces IP i evitar que les sol·licituds arribin al teu servei filtrant a través del tallafocs.
Tot i que és un procés manual, els proveïdors moderns de serveis en el núvol et donen accés a eines que bloquegen possibles atacs . Per exemple, si estàs allotjant els teus serveis en els serveis web d’Amazon, l’Escut d’AWS ajudaria a protegir el teu servidor de possibles atacs.
3.- Utilitza tokens de falsificació de sol·licitud (CSRF)
a l’usar tokens CSRF a la teva aplicació, s’evita que les eines automatitzades realitzin sol·licituds arbitràries a les URL dels convidats. Un testimoni CSRF pot estar present com un camp de formulari ocult.
Per sortejar un símbol CSRF, cal carregar i analitzar el marcatge i buscar el testimoni correcte, abans de agrupar juntament amb la sol·licitud. Aquest procés requereix habilitats de programació i l’accés a eines professionals.
4.- Utilitza el fitxer .htaccess per evitar el raspat
.htaccess és un fitxer de configuració per al teu servidor web . I es pot modificar per evitar que els raspadors accedeixin a les vostres dades. El primer pas és identificar els raspadors, que es pot realitzar a través de Google Webmasters.
Una vegada que els hagis identificat, pots utilitzar moltes tècniques per aturar el procés de raspat canviant el fitxer de configuració. En general, aquest fitxer no està habilitat pel que has d’estar habilitat, només així s’interpretaran els arxius que tu col·locaràs en el teu directori.
5.- Prevenir hotlinking
Quan es raspa el teu contingut, els enllaços en línia a les imatges i altres arxius es copien directament en el lloc de l’atacant. Quan es mostra el mateix contingut en el lloc de l’atacant, dit recurs es vincula directament al teu lloc web.
Aquest procés de mostrar un recurs que està allotjat al servidor en un lloc web diferent es diu hotlinking. Quan evites un enllaç actiu, una imatge d’aquest tipus, quan es mostra en un lloc diferent, no es fa a través del teu servidor.
6.- Direccions IP específiques de llistes negres
Si has identificat les adreces IP o els patrons d’adreces IP que s’utilitzen per raspar, simplement pots bloquejar-a través del teu .htaccess.
7.- Limita el nombre de sol·licituds d’una adreça IP
Com a alternativa, també pots limitar el nombre de sol·licituds d’una adreça IP. Tot i que pot no ser útil si un atacant té accés a diverses adreces IP. També es pot usar un en cas de sol·licituds anormals d’una adreça IP.
El que has de fer és bloquejar l’accés des de les adreces IP conegudes de el servei d’allotjament i rastreig en el núvol per assegurar-se que un atacant no pugui usar aquest servei per eliminar o copiar les dades.
8.- Crear “honeypots”
Un “honeypot” és un enllaç a contingut fals que és invisible per a un usuari normal, però està present en l’HTML. apareixeria quan un programa analitza el lloc web.A l’redirigir un raspador a aquests honeypots, pot detectar raspadors i fer que malgastin recursos a l’visitar pàgines que no contenen dades.
Per tant, no oblidis desactivar aquests enllaços al teu fitxer robots.txt per assegurar-te que un cercador de motors de cerca no acabi en tals honeypots.
9.- Canviar l’estructura de l’HTML amb freqüència
la majoria dels rastrejadors analitzen l’HTML que s’obté de servidor. Per dificultar l’accés dels raspadors a les dades, pots canviar amb freqüència l’estructura de l’HTML. Per fer-ho, un atacant ha d’avaluar novament l’estructura del teu lloc web per extreure les dades. Una altra de les claus per saber què és el web scraping.
10.- Proporcionar API
Pots permetre l’extracció selectiva de dades del teu lloc si estableixes certes regles. Una manera és crear APIs basades en subscripcions per monitoritzar i donar accés a les teves dades. A través de les APIs, també podràs supervisar i restringir l’ús de el servei que ofereixes.
Si no vols tenir problemes de web scraping ni complicacions de cap tipus sempre has de confiar en plataformes que et aportin la seguretat. I que a més, t’ofereixin els serveis que necessites per a cada campanya de màrqueting. I en Antevenio et podem ajudar en aquest sentit. Confia en els nostres serveis de Branded & Content Màrqueting i veuràs com et resultarà fàcil i efectiu.