Transfert de connaissances (transfert de connaissances)
Basé sur l’exemple 5.3 du chollet en F, apprentissage profond avec Python, Ed Manning, 2018
Mariano Rivera
Version 1.0
Mars 2019
import osos.environ="PCI_BUS_ID";os.environ="1"; import keraskeras.__version__Using TensorFlow backend.'2.2.4'VGG16: Un préréglage de réseau de convolutions
Une stratégie pour traiter les réseaux de neurones profondes est d’utiliser des réseaux précédemment pré-comptent avec de grandes bases de données et de les adapter au problème de notre intérêt.
À cette fin, il est nécessaire que le réseau préalable à l’intention ait été formé pour résoudre un problème de nature plus générale, à partir de laquelle notre problème peut être considéré comme un cas particulier. Par exemple, pour le cas de chiens et de chats classifiés, nous pouvons utiliser un réseau qualifié pour classer davantage de classes que le soi-disant VGG16 (Simonyan et Zisserman, 2015). Les raisons que nous utilisons VGG16 sont les suivantes
-
possède une architecture facile à comprendre et, le cas échéant, à mettre en œuvre.
-
Atteindre un excellent résultat dans la compétition Imagenet (ILSVRC-2014), entre 96% et 97%.
-
contient relativement peu de couches convolutionnelles: 13 couches de convolutions et 3 couches de convolutions et 3 denses, Par conséquent, dans son nom, on comprend 16.
-
Le réseau (modèle et pesos formés) Cette diomponible à Kera
( Simonyan et Zisserman, 2015) K. Simonyan et A. Zisserman, des réseaux de convolution très profonds pour une reconnaissance d’images à grande échelle, 3e ICLR 2015.
Réseaux diponables à Keras qui ont été formés dans la BD Imagenet sont
- xception
- inceptionv3
- vgg16
- vgg19
- mobilenet
Le réseau VGG19 est une variante avec plus de calques de calcul que le VGG16, donc plus lourd que stocké dans la mémoire et les exigences de calcul.
Co. MO que nous voyons, puisque VGG16 a été formée pour résoudre le problème de classement de 1 000 clefs dans Imagenet, il doit dans ses pondérations d’encoder des informations pour extraire des fonctionnalités de classies très différentes de représentées dans les photographies de plus de 1,4 million d’Imagenet. Parmi ces classes, il existe des variétés d’animaux très différentes, dans des environnements très différents. Par conséquent, VGG16 est un très bon candidat à être particularisé au problème de la classification binaire des chiens et des chats.
Nous notons qu’il existe des performances plus modernes, meilleures, mais VGG16 servira très bien à notre objectif. Comme nous l’avons vu dans les exemples précédents, les réseaux de convolution pour la classification suivent une structure à deux blocs:
-
étape des couches converties pour extraction de fonctionnalités
-
Étape de décision dense sur couche de couche.
VGG16 Cette architecture continue fidèlement. Afficher la figure Siginete
Utilisation de VGG16 précédemment formée auprès de la BD Imagenet nous permet de supposer que son stade d’extraction des fonctionnalités, efficacement, les relations épaceciales qui rendent les objets distinctifs et la rédaction d’Imagenet, nous font supposer que ces relations spatiales sont suffisamment génériques pour pouvoir codifier des caractéristiques distinctives des chiens et des chats.
Nous allons passer à l’étape Étape, nous avons chargé le réseau VGG16 dans l’emballage keras.applications.
Accès aux composants d’un réseau de convolvols prétendu
Voyons comment Chargez un modèle prédéfini et, comme nous pouvons accéder à ses composants. À titre d’illustration, nous définissons notre version de la fonction summary des modèles Keras. Avec cela, nous montrons comment l’accès aux noms des couches, leur nombre de paramètres, etc.
def resumen(model=None): ''' ''' header = '{:4} {:16} {:24} {:24} {:10}'.format('#', 'Layer Name','Layer Input Shape','Layer Output Shape','Parameters' ) print('='*(len(header))) print(header) print('='*(len(header))) count=0 count_trainable=0 for i, layer in enumerate(model.layers): count_trainable += layer.count_params() if layer.trainable else 0 input_shape = '{}'.format(layer.input_shape) output_shape = '{}'.format(layer.output_shape) str = '{:<4d} {:16} {:24} {:24} {:10}'.format(i,layer.name, input_shape, output_shape, layer.count_params()) print(str) count += layer.count_params() print('_'*(len(header))) print('Total Parameters : ', count) print('Total Trainable Parameters : ', count_trainable) print('Total No-Trainable Parameters : ', count-count_trainable) vgg16=Nonepuis chargez le modèle VGG16 avec les paramètres suivants:
-
Les poids indiquent que les poids seront utilisés pour initialiser le modèle
-
Inclure_top indique si le réseau complet est chargé (extraction des caractéristiques et étape de la décision) ou uniquement l’étage d’extraction des sujets
-
INPUT_PHAPE La forme des images à traiter (facultatif, puisque le réseau que vous pouvez traiter toute dimension d’image)
from keras.applications import VGG16vgg16 = VGG16(weights='imagenet', include_top=True, input_shape=(224, 224, 3))resumen(vgg16)==================================================================================# Layer Name Layer Input Shape Layer Output Shape Parameters==================================================================================0 input_5 (None, 224, 224, 3) (None, 224, 224, 3) 01 block1_conv1 (None, 224, 224, 3) (None, 224, 224, 64) 17922 block1_conv2 (None, 224, 224, 64) (None, 224, 224, 64) 369283 block1_pool (None, 224, 224, 64) (None, 112, 112, 64) 04 block2_conv1 (None, 112, 112, 64) (None, 112, 112, 128) 738565 block2_conv2 (None, 112, 112, 128) (None, 112, 112, 128) 1475846 block2_pool (None, 112, 112, 128) (None, 56, 56, 128) 07 block3_conv1 (None, 56, 56, 128) (None, 56, 56, 256) 2951688 block3_conv2 (None, 56, 56, 256) (None, 56, 56, 256) 5900809 block3_conv3 (None, 56, 56, 256) (None, 56, 56, 256) 59008010 block3_pool (None, 56, 56, 256) (None, 28, 28, 256) 011 block4_conv1 (None, 28, 28, 256) (None, 28, 28, 512) 118016012 block4_conv2 (None, 28, 28, 512) (None, 28, 28, 512) 235980813 block4_conv3 (None, 28, 28, 512) (None, 28, 28, 512) 235980814 block4_pool (None, 28, 28, 512) (None, 14, 14, 512) 015 block5_conv1 (None, 14, 14, 512) (None, 14, 14, 512) 235980816 block5_conv2 (None, 14, 14, 512) (None, 14, 14, 512) 235980817 block5_conv3 (None, 14, 14, 512) (None, 14, 14, 512) 235980818 block5_pool (None, 14, 14, 512) (None, 7, 7, 512) 019 flatten (None, 7, 7, 512) (None, 25088) 020 fc1 (None, 25088) (None, 4096) 10276454421 fc2 (None, 4096) (None, 4096) 1678131222 predictions (None, 4096) (None, 1000) 4097000__________________________________________________________________________________Total Parameters : 138357544Total Trainable Parameters : 138357544Total No-Trainable Parameters : 0vg16_fulull
comporte environ 139 millions de paramètres. Il a vraiment consommé le temps de décharger le modèle complet (ce n’est que pour la première fois que la fonction VGG16 est invoquée. Nous notons que, heureusement, bon nombre des paramètres (tels que 90%) correspondent à l’étape de décision. L’extraction de trait L’étape (illustrée dans la figure suivante) a moins de paramètres.
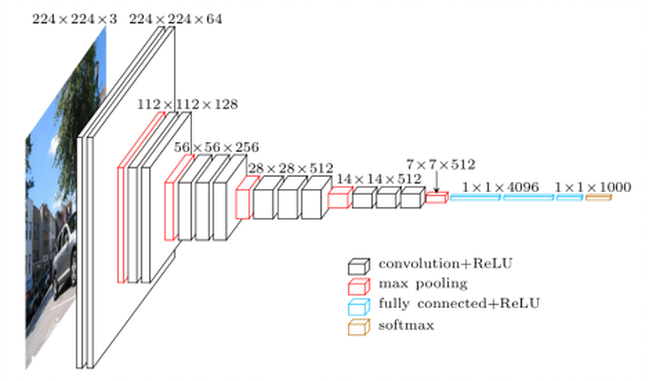
(image prise du réseau, utilisé dans plusieurs blogs, comme dans l’illustration VGG16)
Pour éviter de charger des couches que nous n’utiliserons pas, nous pouvons appeler la méthode avec le paramètre include_top=False et pour la taille spécifique que nous avons utilisée (150 × 150150 \ Times 150150 × 150 pixels)
if vgg16 != None: del vgg16 from keras.applications import VGG16conv_base = VGG16(weights='imagenet', include_top=False, input_shape=(150, 150, 3)) resumen(conv_base) est « seulement » de moins de 15 millions de paramètres, une réduction substantielle par rapport à la VGG16 complète16 Réseau.
Voir le Résumé du réseau Keras
#conv_base.summary() La sortie finale du modèle de base chargé (conv_base) avoir le formulaire (4, 4, 512).
Network pré-entré comme extracteur Caractéristiques hors ligne
La première stratégie que nous utiliserons Pour la réutilisation des connaissances stockées (acquises) par un réseau de classification et la particularité à notre volonté de considérer l’extraction de traits indépendants de la classification ion. C’est une approche de type sombre (par opposition à la profonde). C’est-à-dire que nous allons passer les images sur le réseau de convolvol de base (conv_base) et stocker les caractéristiques de la mémoire ou du disque (ce qui est efficace de calcul), puis de l’alimentation avec un classificateur. Ceci est illustré dans la figure suivante.

Pour générer le codage (dentelle ou l’encreur) des images de chiens et des chats que nous Utilisera un générateur
Il est important si nous utilisons la préprocession VGG16, les données (images) pour les normaliser avec la même procédure utilisée pour former le réseau d’origine. Dans ce cas, il ne s’agit pas de les sauver à l’intervalle, mais de soustraire la moyenne de chaque canal de couleur
import osimport numpy as npfrom tqdm import tqdmfrom keras.applications.imagenet_utils import preprocess_input#from tqdm import tqdm_notebook as tqdmfrom keras.preprocessing.image import ImageDataGeneratorbase_dir = '/home/mariano/Data/dogs_vs_cats_small'#base_dir = '/home/mariano/Documents/deep/kaggle/dogs_vs_cats_small'train_dir = os.path.join(base_dir, 'train')validation_dir = os.path.join(base_dir, 'validation')test_dir = os.path.join(base_dir, 'test')datagen = ImageDataGenerator(#rescale=1./255) preprocessing_function=preprocess_input)batch_size = 20def extract_features(directory, sample_count): ''' Codificador de imagenes mediante conv_base en rasgos para posteriormente usarlos como datos para una red clasificadora densa parámetros directory directorio con con los subdirectorios que definen clases sample_count número de muestras a generar resultados conjunto de características y etiquetas ''' # memoria para tensores con datos y etiquetas features = np.zeros(shape=(sample_count, 4, 4, 512)) labels = np.zeros(shape=(sample_count)) # instanciación del generador a partir del directorio donde estan las clases generator = datagen.flow_from_directory(directory, target_size = (150, 150), batch_size = batch_size, class_mode = 'binary') rango = list(range(int(sample_count/batch_size))) i = 0 with tqdm(total=len(rango)) as pbar: for inputs_batch, labels_batch in tqdm(generator): # características predichas (codificadas) por la subred base # para las imágenes generadas (aumentadas) en lote features_batch = conv_base.predict(inputs_batch) # datos y etiquetas features = features_batch labels = labels_batch i += 1 if i * batch_size >= sample_count: # La ejecucion del generador debe terminarse explícitamente después # usar todas la imágenes break pbar.update(1) return features, labelsensemble de traits de données pour la formation, validation et test
train_features, train_labels = extract_features(train_dir, 2000)validation_features, validation_labels = extract_features(validation_dir, 1000)test_features, test_labels = extract_features(test_dir, 1000) 0%| | 0/100 0%| | 0/100 3%|▎ | 3/100 ... 99%|█████████▉| 99/100 2%|▏ | 1/50 ... 98%|█████████▊| 49/50 2%|▏ | 1/50 ... 98%|█████████▊| 49/50 )import timetstart = time.time()history = model.fit(train_features, train_labels, epochs = 30, batch_size = 20, validation_data = (validation_features, validation_labels), verbose = 2)print('seconds=', time.time()-tstart) La formation est très rapide Étant donné que le réseau de classification ne consiste que de deux couches Dense.
Les courbes de la valeur de la fonction cible et de la précision (accuracy) Ils sont montrés ci-dessous.
import matplotlib.pyplot as pltacc = history.historyval_acc = history.historyloss = history.historyval_loss = history.historyepochs = range(len(acc))plt.plot(epochs, acc, 'bo', label='Entrenamiento acc')plt.plot(epochs, val_acc, 'b', label='Validación acc')plt.title('Accuracy - exactitud de entrenamiento y validación')plt.legend()plt.figure()plt.plot(epochs, loss, 'bo', label='Entrenamiento loss')plt.plot(epochs, val_loss, 'b', label='Validación loss')plt.title('Loss - función objetivo en entrenamiento y prueba')plt.legend()plt.show() 
La vallation atteint 90% de précision, beaucoup mieux que le modèle formé avec une augmentation de données et la paquetée BD qui a atteint 86%.
La courbe de précision illustre que très bientôt, vous commencez à avoir un survêtement (survêtement). C’est parce que nous n’utilisons pas d’augmentation.
Pour mettre en œuvre une augmentation, nous devons faire en sorte que l’extraction des traits soit effectuée en même temps que nous classons, comme modèle complet. Eh bien, dans la mémoire ou le disque, il serait impraticable de stocker les données accrues pour sa classification ultérieure. Ceci est expliqué ci-dessous.
Transférences de connaissances réseau à de nouveaux problèmes
Le modèle CONV_BASE en tant que couche d’extraction de suppression
Si nous supposons que la phase de conviceny VGG16 extrait les caractéristiques générales, ce sera cette partie que nous pouvons réutiliser. Les fonctionnalités extraites doivent être transmises à un nouveau classificateur binaire que nous devons mettre en œuvre et former l’ex-profession. Ce processus est MUSTRA dans la figure suivante

Comme la figure illustre,
-
Nous réutilisons uniquement la phase convolutionnelle du réseau.
-
Nous définissons une nouvelle étape de classification selon notre problème.
-
Depuis que nous avons, relativement, peu de données de formation, définissez le sous-réseau de l’extraction des fonctionnalités (geler leurs poids) pour les empêcher d’être modifié en formation.
- Nous nous entraînons Les poids «viables», ceux de la scène de classement qui effectuent nos données via tout le réseau.
Nous utiliserons des générateurs de données pour effectuer une formation avec des générateurs (fit_generator), comme dans l’exemple de la section précédente.
à Keras Tout sont des calques (couches), nous allons donc utiliser le modèle conv_base comme première couche du réseau, une couche qui calcule les fonctionnalités.
Ajoutez ensuite au nouveau modèle de couches séquentielles classant le modèle Draps Doras.
Cette technique Bien que simple à mettre en œuvre la honte que chaque image augmente soit passée via le réseau conv_base, puis à travers la trieuse. Cela provoque des calculs plus chers et il n’est pas possible de les exécuter dans la CPU, nous avons besoin d’un GPU.
model.reset_states()from keras import modelsfrom keras import layersmodel = models.Sequential()model.add(conv_base) # modelo base agradado como una capa!model.add(layers.Flatten())model.add(layers.Dense(256, activation='relu'))#model.add(layers.Dropout(0.3)) # a vermodel.add(layers.Dense(1, activation='sigmoid'))C’est ce que notre modèle a l’air maintenant:
#model.summary()resumen(model)millions de paramètres, ce qui est très grand. Le classificateur sur l’arrêt ajoute 2 millions d’arrêts supplémentaires.
Avant de former « Nous gèlerons » l’extraction réseau des fonctionnalités car nous avons quelques données et que nous voulons tirer parti des « connaissances » stockées dans le sous-réseau de base VGG16 formé avec de nombreuses classes et devraient être . un très extracteur général des caractéristiques
nous avons atteint en marquant le poids de « la couche » conv_base comme non-formation:
print('Número de pesos (matrices) entrenables antes de congelar conv_base : ', len(model.trainable_weights))Número de pesos (matrices) entrenables antes de congelar conv_base : 30conv_base.trainable = Falseprint('Número de pesos (matrices) entrenables después de congelar conv_base : ', len(model.trainable_weights))Número de pesos (matrices) entrenables después de congelar conv_base : 4resumen(model)==================================================================================# Layer Name Layer Input Shape Layer Output Shape Parameters==================================================================================0 vgg16 (None, 150, 150, 3) (None, 4, 4, 512) 147146881 flatten_1 (None, 4, 4, 512) (None, 8192) 02 dense_3 (None, 8192) (None, 256) 20974083 dense_4 (None, 256) (None, 1) 257__________________________________________________________________________________Total Parameters : 16812353Total Trainable Parameters : 2097665Total No-Trainable Parameters : 14714688Le nombre de matrices dépasse les couches parce que chaque couche peut avoir une matrice de poids www et un vecteur de BIAS BBB.
pour les données figées , nous devons compiler le modèle, puis définir les paramètres pour le générateur.
from keras.preprocessing.image import ImageDataGeneratorfrom keras import modelsfrom keras import layersfrom keras import optimizerstrain_datagen = ImageDataGenerator(#rescale = 1./255, preprocessing_function=preprocess_input, rotation_range = 40, width_shift_range = 0.2, height_shift_range= 0.2, shear_range = 0.2, zoom_range = 0.2, horizontal_flip = True, fill_mode = 'constant', #'nearest') cval = 0)# La validación no se aumenta!test_datagen = ImageDataGenerator(#rescale=1./255) preprocessing_function=preprocess_input)train_generator = train_datagen.flow_from_directory( train_dir, # directorio con datos de entrenamiento target_size= (150, 150), # tamaño de la imágenes batch_size = 20, shuffle = True, class_mode = 'binary') # para clasificación binariavalidation_generator = test_datagen.flow_from_directory( validation_dir, target_size=(150, 150), batch_size=20, class_mode='binary')model.compile(loss='binary_crossentropy', optimizer=keras.optimizers.Nadam(lr=2e-5), #optimizers.RMSprop(lr=2e-5), metrics=)#model.reset_states()import timetstart = time.time()history = model.fit_generator(train_generator, steps_per_epoch = 100, epochs = 30, validation_data = validation_generator, validation_steps= 50, verbose = 2)print('seconds=', time.time()-tstart)Found 2000 images belonging to 2 classes.Found 1000 images belonging to 2 classes.Epoch 1/30 - 10s - loss: 1.9860 - acc: 0.7660 - val_loss: 0.7680 - val_acc: 0.9040Epoch 2/30 - 9s - loss: 0.9115 - acc: 0.8815 - val_loss: 0.5760 - val_acc: 0.9210...Epoch 30/30 - 9s - loss: 0.1956 - acc: 0.9640 - val_loss: 0.3213 - val_acc: 0.9660seconds= 281.5276675224304model.save('cats_and_dogs_small_3.h5')Graphiquement représenter graphiquement le comportement des paramètres enregistrés au cours de la Nation
import matplotlib.pyplot as pltacc = history.historyval_acc = history.historyloss = history.historyval_loss = history.historyepochs = range(len(acc))plt.plot(epochs, acc, 'bo', label='Entrenamiento acc')plt.plot(epochs, val_acc, 'b', label='Validación acc')plt.title('Accuracy - exactitud de entrenamiento y validación')plt.legend()plt.figure()plt.plot(epochs, loss, 'bo', label='Entrenamiento loss')plt.plot(epochs, val_loss, 'b', label='Validación loss')plt.title('Loss - función objetivo en entrenamiento y prueba')plt.legend()plt.show() 
PNG
Selon l’auteur du livre (chollet), une précision de près de 96,5% est atteinte.
Réglage fin
une autre stratégie largement utilisée dans la réutilisation de raffinement est le réglage de fin (réglage fin), ce qui cohérent qui, une fois une couche de classification avec pretrenetranda, a été formé, Defrost la Dernières couches de la base convolutionnaire pour permettre à leur poids de mieux s’adapter à la couche de classification. Atteindre une meilleure intégration entre la base (formée à un problème différent) et la classification.
Les étapes de la formation fine sont les suivantes:
- Ajouter à une base de convicenale générale une étape classement final.
- Figer la base convolutionnel.
- Formation de l’étape de tri.
- dégivrer les dernières couches de la base convolutionnel.
- Traîner la scène de tri et les dernières couches de la convolutionnelle ensemble.
partido du modèle précédent précédent (étapes 1,2 et 3) Nous voyons que les couches de dégel sont celles correspondant à la bloc5.
Pour rappel le résumé de la convolution est
resumen(conv_base)==================================================================================# Layer Name Layer Input Shape Layer Output Shape Parameters==================================================================================0 input_6 (None, 150, 150, 3) (None, 150, 150, 3) 01 block1_conv1 (None, 150, 150, 3) (None, 150, 150, 64) 17922 block1_conv2 (None, 150, 150, 64) (None, 150, 150, 64) 369283 block1_pool (None, 150, 150, 64) (None, 75, 75, 64) 04 block2_conv1 (None, 75, 75, 64) (None, 75, 75, 128) 738565 block2_conv2 (None, 75, 75, 128) (None, 75, 75, 128) 1475846 block2_pool (None, 75, 75, 128) (None, 37, 37, 128) 07 block3_conv1 (None, 37, 37, 128) (None, 37, 37, 256) 2951688 block3_conv2 (None, 37, 37, 256) (None, 37, 37, 256) 5900809 block3_conv3 (None, 37, 37, 256) (None, 37, 37, 256) 59008010 block3_pool (None, 37, 37, 256) (None, 18, 18, 256) 011 block4_conv1 (None, 18, 18, 256) (None, 18, 18, 512) 118016012 block4_conv2 (None, 18, 18, 512) (None, 18, 18, 512) 235980813 block4_conv3 (None, 18, 18, 512) (None, 18, 18, 512) 235980814 block4_pool (None, 18, 18, 512) (None, 9, 9, 512) 015 block5_conv1 (None, 9, 9, 512) (None, 9, 9, 512) 235980816 block5_conv2 (None, 9, 9, 512) (None, 9, 9, 512) 235980817 block5_conv3 (None, 9, 9, 512) (None, 9, 9, 512) 235980818 block5_pool (None, 9, 9, 512) (None, 4, 4, 512) 0__________________________________________________________________________________Total Parameters : 14714688Total Trainable Parameters : 14714688Total No-Trainable Parameters : 0 Nous allons faire l’ajustement de fin sur les trois dernières couches convolutionary:. block5_conv1 block5_conv2 et block5_conv3
il est important de noter que le premier code des couches plus d’ informations générales il ne convient pas Renectez-les si le but est de réutiliser la connaissance. Nous finirions de surveiller le modèle à de petites nustras BD.
# Orden de las capas for layer in conv_base.layers: print(layer.name)conv_base.trainable = Trueset_trainable = Falsefor layer in conv_base.layers: if layer.name in : layer.trainable = True else: layer.trainable = False resumen(conv_base) ==================================================================================# Layer Name Layer Input Shape Layer Output Shape Parameters==================================================================================0 input_6 (None, 150, 150, 3) (None, 150, 150, 3) 01 block1_conv1 (None, 150, 150, 3) (None, 150, 150, 64) 17922 block1_conv2 (None, 150, 150, 64) (None, 150, 150, 64) 369283 block1_pool (None, 150, 150, 64) (None, 75, 75, 64) 04 block2_conv1 (None, 75, 75, 64) (None, 75, 75, 128) 738565 block2_conv2 (None, 75, 75, 128) (None, 75, 75, 128) 1475846 block2_pool (None, 75, 75, 128) (None, 37, 37, 128) 07 block3_conv1 (None, 37, 37, 128) (None, 37, 37, 256) 2951688 block3_conv2 (None, 37, 37, 256) (None, 37, 37, 256) 5900809 block3_conv3 (None, 37, 37, 256) (None, 37, 37, 256) 59008010 block3_pool (None, 37, 37, 256) (None, 18, 18, 256) 011 block4_conv1 (None, 18, 18, 256) (None, 18, 18, 512) 118016012 block4_conv2 (None, 18, 18, 512) (None, 18, 18, 512) 235980813 block4_conv3 (None, 18, 18, 512) (None, 18, 18, 512) 235980814 block4_pool (None, 18, 18, 512) (None, 9, 9, 512) 015 block5_conv1 (None, 9, 9, 512) (None, 9, 9, 512) 235980816 block5_conv2 (None, 9, 9, 512) (None, 9, 9, 512) 235980817 block5_conv3 (None, 9, 9, 512) (None, 9, 9, 512) 235980818 block5_pool (None, 9, 9, 512) (None, 4, 4, 512) 0__________________________________________________________________________________Total Parameters : 14714688Total Trainable Parameters : 7079424Total No-Trainable Parameters : 7635264 Notez maintenant que le conv_base dont la formation et non trainable parampers.
Pour la formation fine nous procédons à la compilation du modèle avec une petite taille de pas pour éviter d’ importantes modifications de poids, puisque nous supposons qu’il est proche de l’optimum et l’ajustement ne doit pas être très grande.
Epoch 1/100100/100 - 10s 104ms/step - loss: 0.1938 - acc: 0.9645 - val_loss: 0.2769 - val_acc: 0.9580Epoch 2/100100/100 - 9s 94ms/step - loss: 0.2239 - acc: 0.9635 - val_loss: 0.2606 - val_acc: 0.9650... Epoch 100/100100/100 - 10s 97ms/step - loss: 0.0269 - acc: 0.9960 - val_loss: 0.3666 - val_acc: 0.9620model.save('cats_and_dogs_small_4.h5')Metrics graphiques enregistrés au cours de la formation
import matplotlib.pyplot as pltacc = history.historyval_acc = history.historyloss = history.historyval_loss = history.historyepochs = range(len(acc))plt.plot(epochs, acc, 'bo', label='Entrenamiento acc')plt.plot(epochs, val_acc, 'b', label='Validación acc')plt.title('Accuracy - exactitud de entrenamiento y validación')plt.legend()plt.figure()plt.plot(epochs, loss, 'bo', label='Entrenamiento loss')plt.plot(epochs, val_loss, 'b', label='Validación loss')plt.title('Loss - función objetivo en entrenamiento y prueba')plt.legend()plt.show() 

Étant donné que les courbes sont très bruyants, il est possible de les filtrer pour mieux apprécier la tendance au moyen d’un filtre passe-bas, on pourrait essayer
s ~ i = rk = 0NWksi-k \ tilde S_I = \ sum_ {k = 0} ^ n w_k S_ {IK} S ~ i = K = 0ΣNWKSI-K
Où sont www un pesos co n σkwk = 1 \ sum_k w_k = 1σkwk = 1; Mais nous aurons besoin d’un filtre assez large (grand NNN) pour éliminer correctement le bruit, nous essayons la version récursive (comme dans le livre sur lequel ces notes sont basées)
i
s ~ i = aS ~ i -1+ (1-α) Si \ tilde S_I = \ alpha \ tilde {S_ I-1} + (1- α) S_IS ~ I = aS ~ i-1 + (1-α) si
que vous utilisez les données récemment mises à jour avec une procédure similaire. Ces filtres récursifs peuvent être exprimés comme non récursif (remplacement des données mises à jour par sa formule). L’avantage de la forme récursive est le compact d’expression de mise à jour
def smooth_curve(points, factor=0.8): smoothed_points = for point in points: if smoothed_points: previous = smoothed_points smoothed_points.append(previous * factor + point * (1 - factor)) else: smoothed_points.append(point) return smoothed_pointsimport matplotlib.pyplot as pltacc = history.historyval_acc = history.historyloss = history.historyval_loss = history.historyepochs = range(len(acc))alpha = 0.9plt.plot(epochs, smooth_curve(acc, alpha), 'bo', label='Entrenamiento acc')plt.plot(epochs, smooth_curve(val_acc, alpha), 'b', label='Validación acc')plt.title('Accuracy - exactitud de entrenamiento y validación')plt.legend()plt.figure()plt.plot(epochs, smooth_curve(loss, alpha), 'bo', label='Entrenamiento loss')plt.plot(epochs, smooth_curve(val_loss,alpha), 'b', label='Validación loss')plt.title('Loss - función objetivo en entrenamiento y prueba')plt.legend()plt.show() 

Dans ces courbes , vous pouvez mieux apprécier la tendance, on peut remarquer que c’était une amélioration d’environ 1%.
Dans (Chollet, 2018), l’observation est faite que la précision s’améliore même lorsque la perte ne le fait pas. En effet , la perte est évaluée par un processus de somme d’erreur dans le vecteur de sortie, quelque chose comme:
Σi∈epoch∥yi-y ^ i∥m \ sum_ {i \ in EPOCH} \ | Y_i – \ chapeau y_i \ | _mi∈epoch∥∥yi-y ^ i∥m
où nous supposons que YYY est dans un codage à une fois à chaud et M indique une métrique.D’autre part, la précision est calculée au moyen d’une somme de classement des erreurs:
σi∈epoch1-δ (argmaxiyi-argmaxiy ^ i) \ sum_ {i \ in epoch } 1- δ (τ \ rm \ max_i {\ chapeau y_i}) ∈epochς1-δ (argimaxyi-argimaxy ^ i)
Evaluez, enfin et péris, le jeu de test:
test_generator = test_datagen.flow_from_directory( test_dir, target_size=(150, 150), batch_size=20, class_mode='binary')test_loss, test_acc = model.evaluate_generator(test_generator, steps=50)print('test acc:', test_acc)Found 1000 images belonging to 2 classes.test acc: 0.9669999933242798* très proche de 97%
dans la compétition de kaggle d’origine, ce serait parmi les meilleurs résultats (top), et que nous n’utilisons que 2000 données de formation vs. 20 000 dans la compétition de Kaggle.
Résumé
-
Les réseaux de convolutionnels sont le meilleur modèle de réseaux neuronaux pour traiter les problèmes de traitement des images et de vision informatique.
-
L’augmentation des données vous permet d’éviter de discuter dans une petite base de données et d’augmenter avec les données synthétiques de la taille de l’échantillon de formation
-
c’est possible Pour utiliser des modèles pré-endigents dans la phase d’extraction des fonctionnalités pour traiter de petites bases de données.
-
Le réglage fin permet d’améliorer l’interconnexion du stade prédéfini avec le stade de la stade de la stade de la stade de la stade de la stade performance à faible coût de calcul.