Transferência de conhecimento (transferência de conhecimento)
com base no Exemplo 5.3 de F Chocolete, Aprendizagem Profunda com Python, Ed Manning, 2018
Mariano Rivera
versão 1.0 de março de 2019
import osos.environ="PCI_BUS_ID";os.environ="1"; import keraskeras.__version__Using TensorFlow backend.'2.2.4'vgg16: uma prática de rede de convoluções
Uma estratégia para lidar com redes neurais profundas é usar redes anteriormente pré-atidas com grandes bancos de dados e adaptá-los ao problema de nossos juros.
Para esta finalidade é necessário que a rede pré-intenção tenha sido treinada para resolver um problema de uma natureza mais geral, da qual nosso problema pode ser considerado um caso particular. Por exemplo, para o caso de classificar cães e gatos, podemos usar uma rede treinada para classificar mais classes como a chamada VGG16 (Simonyan e Zisserman, 2015). As razões que usamos VGG16 são as seguintes
tem uma arquitetura fácil de entender e, se aplicável, implementar.
atingir um excelente resultado na concorrência do ImageNet (ILSVRC-2014), entre 96% e 97%.
contém relativamente poucas camadas convolucionais: 13 camadas convolucionárias e 3 densas, Assim, em seu nome incluem 16.
A rede (modelo e pesos treinados) este diponible em kera
( Simonyan e Zisserman, 2015) K. Simonyan e A. Zisserman, redes de convolução muito profundas para reconhecimento de imagem em larga escala, 3º ICLR 2015.
redes diponíveis em keras que foram treinados no BD Imagenet são
- xception
- intoceptv3
- vgg16
- vgg19
- mobilenet
A rede VGG19 é uma variante com mais camadas de cálculo do que o VGG16, portanto mais pesado do que os requisitos de memória e computação.
Co. MO vemos, já que a VGG11 foi treinada para resolver o problema de ranking de 1000 clad no ImageNet, ele deve em seus pesos codificar informações para extrair recursos de classes muito diferentes, de representarem mais de 1,4 milhão de imagens images. Entre essas classes existem variedades muito diferentes de animais, em ambientes muito diferentes. Portanto, a VGG16 é um candidato muito bom a ser particularizado para o problema da classificação binária de cães e gatos.
Observamos que há mais desempenho moderno, melhor, mas a VGG15 servirá muito bem para o nosso propósito. Como vimos nos exemplos anteriores, as redes convolucionais para classificação seguem uma estrutura de dois blocos:
- etapa de camadas convertidas para extração de recursos
-
Decisão de decisão baseada em camada densa.
vgg16 Esta arquitetura continua fielmente. Ver figura de siginete

Usando o VGG16 previamente treinado com o BD ImageNet nos permite assumir que sua fase de extração de recursos, Efetivamente, as relações epaciais que fazem os objetos distinguíveis e a dívida do ImageNet, nos faz assumir que essas relações espaciais são suficientemente genéricas para serem capazes de codificar características distintivas de cães e gatos.
Vamos passo passo, primeiro carregamos a rede VGG16 no pacote keras.applications.
acesso aos componentes de uma rede de convolva Pretrended
Vamos ver como Carregue um modelo predefinido e conforme podemos acessar seus componentes. Como uma ilustração, definimos nossa versão da função summary dos modelos de keras. Com isso, mostramos como acesso aos nomes das camadas, seu número de parâmetros, etc.
def resumen(model=None): ''' ''' header = '{:4} {:16} {:24} {:24} {:10}'.format('#', 'Layer Name','Layer Input Shape','Layer Output Shape','Parameters' ) print('='*(len(header))) print(header) print('='*(len(header))) count=0 count_trainable=0 for i, layer in enumerate(model.layers): count_trainable += layer.count_params() if layer.trainable else 0 input_shape = '{}'.format(layer.input_shape) output_shape = '{}'.format(layer.output_shape) str = '{:<4d} {:16} {:24} {:24} {:10}'.format(i,layer.name, input_shape, output_shape, layer.count_params()) print(str) count += layer.count_params() print('_'*(len(header))) print('Total Parameters : ', count) print('Total Trainable Parameters : ', count_trainable) print('Total No-Trainable Parameters : ', count-count_trainable) vgg16=NoneEm seguida, carregue o modelo VGG16 com os seguintes parâmetros:
-
Os pesos indica que os pesos serão usados para inicializar o modelo
-
include_toto Indica se a rede completa é carregada (extração de características e Estágio de decisão) ou apenas a fase de extração de assuntos
-
input_shape A forma das imagens a serem processadas (opcional, já que a rede você pode processar qualquer dimensão de imagem)
from keras.applications import VGG16vgg16 = VGG16(weights='imagenet', include_top=True, input_shape=(224, 224, 3))resumen(vgg16)==================================================================================# Layer Name Layer Input Shape Layer Output Shape Parameters==================================================================================0 input_5 (None, 224, 224, 3) (None, 224, 224, 3) 01 block1_conv1 (None, 224, 224, 3) (None, 224, 224, 64) 17922 block1_conv2 (None, 224, 224, 64) (None, 224, 224, 64) 369283 block1_pool (None, 224, 224, 64) (None, 112, 112, 64) 04 block2_conv1 (None, 112, 112, 64) (None, 112, 112, 128) 738565 block2_conv2 (None, 112, 112, 128) (None, 112, 112, 128) 1475846 block2_pool (None, 112, 112, 128) (None, 56, 56, 128) 07 block3_conv1 (None, 56, 56, 128) (None, 56, 56, 256) 2951688 block3_conv2 (None, 56, 56, 256) (None, 56, 56, 256) 5900809 block3_conv3 (None, 56, 56, 256) (None, 56, 56, 256) 59008010 block3_pool (None, 56, 56, 256) (None, 28, 28, 256) 011 block4_conv1 (None, 28, 28, 256) (None, 28, 28, 512) 118016012 block4_conv2 (None, 28, 28, 512) (None, 28, 28, 512) 235980813 block4_conv3 (None, 28, 28, 512) (None, 28, 28, 512) 235980814 block4_pool (None, 28, 28, 512) (None, 14, 14, 512) 015 block5_conv1 (None, 14, 14, 512) (None, 14, 14, 512) 235980816 block5_conv2 (None, 14, 14, 512) (None, 14, 14, 512) 235980817 block5_conv3 (None, 14, 14, 512) (None, 14, 14, 512) 235980818 block5_pool (None, 14, 14, 512) (None, 7, 7, 512) 019 flatten (None, 7, 7, 512) (None, 25088) 020 fc1 (None, 25088) (None, 4096) 10276454421 fc2 (None, 4096) (None, 4096) 1678131222 predictions (None, 4096) (None, 1000) 4097000__________________________________________________________________________________Total Parameters : 138357544Total Trainable Parameters : 138357544Total No-Trainable Parameters : 0
são cerca de 139 milhões de parâmetros. É realmente consumido tempo para descarregar o modelo completo (é feito apenas pela primeira vez que a função VGG16 é invocada. Observamos que, felizmente, muitos dos parâmetros (como 90%) correspondem à etapa de decisão. A extração de característica O estágio (ilustrado na figura a seguir) tem menos parâmetros.
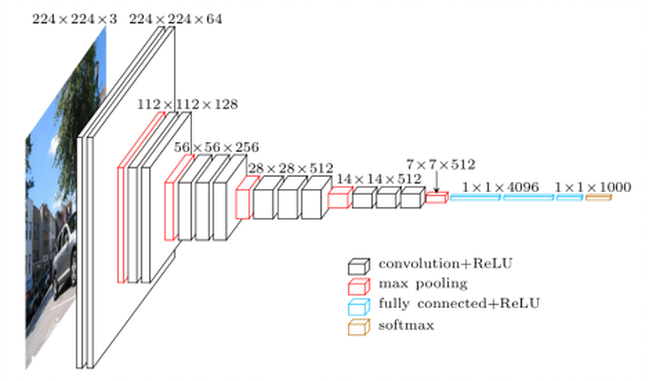
(imagem tirada da rede, usada em vários blogs, como na ilustração vgg16)
Para evitar camadas de carga que não usaremos, podemos invocar o método com o parâmetro include_top=False e para o tamanho específico que usamos (150 × 150150 \ vezes 150150 × 150 pixels)
if vgg16 != None: del vgg16 from keras.applications import VGG16conv_base = VGG16(weights='imagenet', include_top=False, input_shape=(150, 150, 3)) resumen(conv_base) ==================================================================================# Layer Name Layer Input Shape Layer Output Shape Parameters==================================================================================0 input_6 (None, 150, 150, 3) (None, 150, 150, 3) 01 block1_conv1 (None, 150, 150, 3) (None, 150, 150, 64) 17922 block1_conv2 (None, 150, 150, 64) (None, 150, 150, 64) 369283 block1_pool (None, 150, 150, 64) (None, 75, 75, 64) 04 block2_conv1 (None, 75, 75, 64) (None, 75, 75, 128) 738565 block2_conv2 (None, 75, 75, 128) (None, 75, 75, 128) 1475846 block2_pool (None, 75, 75, 128) (None, 37, 37, 128) 07 block3_conv1 (None, 37, 37, 128) (None, 37, 37, 256) 2951688 block3_conv2 (None, 37, 37, 256) (None, 37, 37, 256) 5900809 block3_conv3 (None, 37, 37, 256) (None, 37, 37, 256) 59008010 block3_pool (None, 37, 37, 256) (None, 18, 18, 256) 011 block4_conv1 (None, 18, 18, 256) (None, 18, 18, 512) 118016012 block4_conv2 (None, 18, 18, 512) (None, 18, 18, 512) 235980813 block4_conv3 (None, 18, 18, 512) (None, 18, 18, 512) 235980814 block4_pool (None, 18, 18, 512) (None, 9, 9, 512) 015 block5_conv1 (None, 9, 9, 512) (None, 9, 9, 512) 235980816 block5_conv2 (None, 9, 9, 512) (None, 9, 9, 512) 235980817 block5_conv3 (None, 9, 9, 512) (None, 9, 9, 512) 235980818 block5_pool (None, 9, 9, 512) (None, 4, 4, 512) 0__________________________________________________________________________________Total Parameters : 14714688Total Trainable Parameters : 14714688Total No-Trainable Parameters : 0são “apenas” pouco menos de 15 milhões de parâmetros, uma redução substancial em relação à completa VGG16 rede.
Vamos ver o resumo da rede Keras
#conv_base.summary() A saída final do modelo base carregado (conv_base) tem o formulário (4, 4, 512).
Network pré-inserido como apresentação do extrator Offline
A primeira estratégia que usaremos Para reutilizar o conhecimento armazenado (adquirido) por uma rede classificante e particularizá-lo para a nossa vontade considerando a extração de características independentes da classificação íon. É uma abordagem do tipo sombrio (em oposição ao profundo). Isto é, vamos passar as imagens para a base de convolva a rede (conv_base) e armazenar as características em memória ou disco (que é computacionalmente eficiente) e, em seguida, alimentam com esses recursos de um classificador. Isso é ilustrado na seguinte figura.

para gerar a codificação (renda ou incorporação) de imagens de cão e gatos Usará um gerador
É importante se usarmos o pré-processado VGG16 os dados (imagens) para normalizá-los com o mesmo procedimento usado para treinar a rede original. Neste caso, não é para resgatá-los ao intervalo, mas subtrair a média de cada canal de cor
import osimport numpy as npfrom tqdm import tqdmfrom keras.applications.imagenet_utils import preprocess_input#from tqdm import tqdm_notebook as tqdmfrom keras.preprocessing.image import ImageDataGeneratorbase_dir = '/home/mariano/Data/dogs_vs_cats_small'#base_dir = '/home/mariano/Documents/deep/kaggle/dogs_vs_cats_small'train_dir = os.path.join(base_dir, 'train')validation_dir = os.path.join(base_dir, 'validation')test_dir = os.path.join(base_dir, 'test')datagen = ImageDataGenerator(#rescale=1./255) preprocessing_function=preprocess_input)batch_size = 20def extract_features(directory, sample_count): ''' Codificador de imagenes mediante conv_base en rasgos para posteriormente usarlos como datos para una red clasificadora densa parámetros directory directorio con con los subdirectorios que definen clases sample_count número de muestras a generar resultados conjunto de características y etiquetas ''' # memoria para tensores con datos y etiquetas features = np.zeros(shape=(sample_count, 4, 4, 512)) labels = np.zeros(shape=(sample_count)) # instanciación del generador a partir del directorio donde estan las clases generator = datagen.flow_from_directory(directory, target_size = (150, 150), batch_size = batch_size, class_mode = 'binary') rango = list(range(int(sample_count/batch_size))) i = 0 with tqdm(total=len(rango)) as pbar: for inputs_batch, labels_batch in tqdm(generator): # características predichas (codificadas) por la subred base # para las imágenes generadas (aumentadas) en lote features_batch = conv_base.predict(inputs_batch) # datos y etiquetas features = features_batch labels = labels_batch i += 1 if i * batch_size >= sample_count: # La ejecucion del generador debe terminarse explícitamente después # usar todas la imágenes break pbar.update(1) return features, labelsConjunto de traços de dados para treinamento, validação e teste
train_features, train_labels = extract_features(train_dir, 2000)validation_features, validation_labels = extract_features(validation_dir, 1000)test_features, test_labels = extract_features(test_dir, 1000) 0%| | 0/100 0%| | 0/100 3%|▎ | 3/100 ... 99%|█████████▉| 99/100 2%|▏ | 1/50 ... 98%|█████████▊| 49/50 2%|▏ | 1/50 ... 98%|█████████▊| 49/50 )import timetstart = time.time()history = model.fit(train_features, train_labels, epochs = 30, batch_size = 20, validation_data = (validation_features, validation_labels), verbose = 2)print('seconds=', time.time()-tstart)Train on 2000 samples, validate on 1000 samplesEpoch 1/30 - 1s - loss: 3.3298 - acc: 0.7205 - val_loss: 1.0112 - val_acc: 0.8950...Epoch 30/30 - 0s - loss: 0.0800 - acc: 0.9905 - val_loss: 0.3714 - val_acc: 0.9630seconds= 14.222734451293945 treinamento é muito rápido Dado que a rede de classificação consiste apenas em duas camadas Dense.
As curvas do valor e precisão da função de destino (accuracy) Eles são mostrados abaixo.
import matplotlib.pyplot as pltacc = history.historyval_acc = history.historyloss = history.historyval_loss = history.historyepochs = range(len(acc))plt.plot(epochs, acc, 'bo', label='Entrenamiento acc')plt.plot(epochs, val_acc, 'b', label='Validación acc')plt.title('Accuracy - exactitud de entrenamiento y validación')plt.legend()plt.figure()plt.plot(epochs, loss, 'bo', label='Entrenamiento loss')plt.plot(epochs, val_loss, 'b', label='Validación loss')plt.title('Loss - función objetivo en entrenamiento y prueba')plt.legend()plt.show() 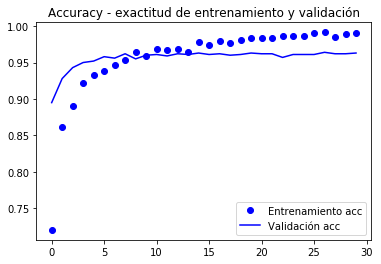
Vallation atinge 90% de precisão, muito melhor do que o modelo treinado com aumento de dados e o BD PAQuea que atingiu 86%.
a curva de precisão ilustra que muito em breve você começa a ter um sobrecarga (sobrecarga). É porque não usamos um aumento.
Implementar o aumento, devemos fazer com que a extração de traços seja feita ao mesmo tempo que classificamos, como modelo completo. Bem, em memória ou disco, seria impraticável armazenar os dados aumentados para sua classificação subseqüente. Isto é explicado abaixo.
Redes de transferência de conhecimento para novos problemas
O modelo Conv_Base como uma camada de extração de remoção
Se assumirmos que o estágio convolucionário do VGG16 Extrai as características gerais, será essa parte que podemos reutilizar. As características extraídas devem ser passadas para um novo classificador binário que devemos implementar e treinar ex-profissão. Este processo é a Mustra na figura a seguir
Como a figura ilustra,
-
Reutimos apenas o estágio convolucionário da rede.
-
Definimos uma nova etapa de classificação de acordo com o nosso problema.
-
Como temos, relativamente, poucos dados de treinamento, definir a sub-rede de extração de recursos (congelar seus pesos) para impedi-los de serem modificados no treinamento.
-
Nós treinamos Os pesos “viáveis”, aqueles da fase de classificação que fazem nossos dados por toda a rede.
Vamos usar os geradores de dados para fazer um treinamento com geradores (fit_generator), como no exemplo da seção anterior.
em Keras Tudo é camadas (camadas), então vamos usar o modelo conv_base como a primeira camada da rede, uma camada que calcula os recursos.
Adicione ao novo modelo de camadas sequenciais Classify Dense Doras.
Esta técnica embora simples para implementar vergonha que cada imagem aumentada é passada através da rede conv_base e depois através do classificador. Isso faz com que os cálculos agora mais caros e não seja possível executá-los na CPU, nós exigimos uma GPU.
model.reset_states()from keras import modelsfrom keras import layersmodel = models.Sequential()model.add(conv_base) # modelo base agradado como una capa!model.add(layers.Flatten())model.add(layers.Dense(256, activation='relu'))#model.add(layers.Dropout(0.3)) # a vermodel.add(layers.Dense(1, activation='sigmoid'))Isto é o que se parece com o nosso modelo agora:
#model.summary()resumen(model)==================================================================================# Layer Name Layer Input Shape Layer Output Shape Parameters==================================================================================0 vgg16 (None, 150, 150, 3) (None, 4, 4, 512) 147146881 flatten_1 (None, 4, 4, 512) (None, 8192) 02 dense_3 (None, 8192) (None, 256) 20974083 dense_4 (None, 256) (None, 1) 257__________________________________________________________________________________Total Parameters : 16812353Total Trainable Parameters : 16812353Total No-Trainable Parameters : 0a rede convolvida da base de VGG16 15 milhões de parâmetros, que é muito grande. O classificador na parada adiciona mais 2 milhões de paradas.
Antes de treinar “nós congelaremos” a extração de recursos dos recursos, uma vez que temos alguns dados e queremos aproveitar o “conhecimento” armazenado na sub-rede base VGG16 que foi treinada com muitas aulas e deve ser Um exaustor geral de recursos.
Isso conseguimos marcando os pesos de “a camada” conv_base como não-treinamento:
print('Número de pesos (matrices) entrenables antes de congelar conv_base : ', len(model.trainable_weights))Número de pesos (matrices) entrenables antes de congelar conv_base : 30print('Número de pesos (matrices) entrenables después de congelar conv_base : ', len(model.trainable_weights))Número de pesos (matrices) entrenables después de congelar conv_base : 4resumen(model)==================================================================================# Layer Name Layer Input Shape Layer Output Shape Parameters==================================================================================0 vgg16 (None, 150, 150, 3) (None, 4, 4, 512) 147146881 flatten_1 (None, 4, 4, 512) (None, 8192) 02 dense_3 (None, 8192) (None, 256) 20974083 dense_4 (None, 256) (None, 1) 257__________________________________________________________________________________Total Parameters : 16812353Total Trainable Parameters : 2097665Total No-Trainable Parameters : 14714688O número de matrizes excede as camadas porque cada camada pode ter uma matriz de peso www e um vetor de Bias BBB.
Para tornar o congelamento de dados, precisamos compilar o modelo e definir os parâmetros para o gerador.
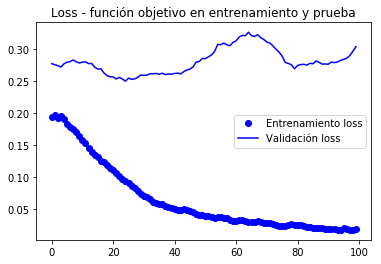
from keras.preprocessing.image import ImageDataGeneratorfrom keras import modelsfrom keras import layersfrom keras import optimizerstrain_datagen = ImageDataGenerator(#rescale = 1./255, preprocessing_function=preprocess_input, rotation_range = 40, width_shift_range = 0.2, height_shift_range= 0.2, shear_range = 0.2, zoom_range = 0.2, horizontal_flip = True, fill_mode = 'constant', #'nearest') cval = 0)# La validación no se aumenta!test_datagen = ImageDataGenerator(#rescale=1./255) preprocessing_function=preprocess_input)train_generator = train_datagen.flow_from_directory( train_dir, # directorio con datos de entrenamiento target_size= (150, 150), # tamaño de la imágenes batch_size = 20, shuffle = True, class_mode = 'binary') # para clasificación binariavalidation_generator = test_datagen.flow_from_directory( validation_dir, target_size=(150, 150), batch_size=20, class_mode='binary')model.compile(loss='binary_crossentropy', optimizer=keras.optimizers.Nadam(lr=2e-5), #optimizers.RMSprop(lr=2e-5), metrics=)#model.reset_states()import timetstart = time.time()history = model.fit_generator(train_generator, steps_per_epoch = 100, epochs = 30, validation_data = validation_generator, validation_steps= 50, verbose = 2)print('seconds=', time.time()-tstart)Found 2000 images belonging to 2 classes.Found 1000 images belonging to 2 classes.Epoch 1/30 - 10s - loss: 1.9860 - acc: 0.7660 - val_loss: 0.7680 - val_acc: 0.9040Epoch 2/30 - 9s - loss: 0.9115 - acc: 0.8815 - val_loss: 0.5760 - val_acc: 0.9210...Epoch 30/30 - 9s - loss: 0.1956 - acc: 0.9640 - val_loss: 0.3213 - val_acc: 0.9660seconds= 281.5276675224304model.save('cats_and_dogs_small_3.h5')Graficamente gráfico o comportamento das métricas registradas durante o nação
import matplotlib.pyplot as pltacc = history.historyval_acc = history.historyloss = history.historyval_loss = history.historyepochs = range(len(acc))plt.plot(epochs, acc, 'bo', label='Entrenamiento acc')plt.plot(epochs, val_acc, 'b', label='Validación acc')plt.title('Accuracy - exactitud de entrenamiento y validación')plt.legend()plt.figure()plt.plot(epochs, loss, 'bo', label='Entrenamiento loss')plt.plot(epochs, val_loss, 'b', label='Validación loss')plt.title('Loss - función objetivo en entrenamiento y prueba')plt.legend()plt.show() 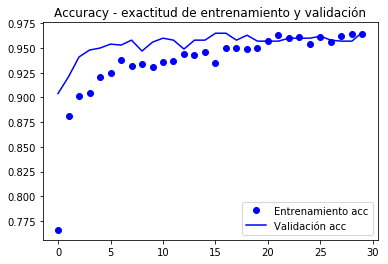
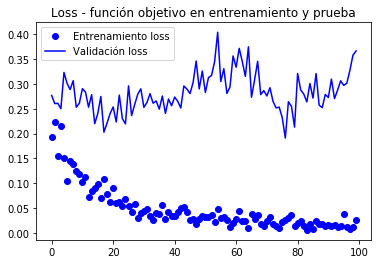
De acordo com o autor do livro (chumbo), uma precisão de cerca de 96,5% é atingida.
ajuste fino
Outra estratégia amplamente utilizada na reutilização de refinamento é o ajuste fino (ajuste fino), que consistente que, uma vez que uma camada de classificação com pré-retrenetrandas, foi treinada, Últimas camadas da base convolucionária para permitir que seus pesos se adaptem melhor à camada de classificação. Alcançar uma melhor integração entre a base (treinada para um problema diferente) e a classificação.
As etapas de treinamento fino são:
- Adicionar a uma base geral convolucionária um estágio Classificação final.
- congelar a base convolucionais.
- treinando o estágio de classificação.
- descongelhar as últimas camadas da base convolucionária.
- Estágio de triagem de trem e últimas camadas do conjunto convolucionário.
Partedo do modelo anterior anterior (etapas 1,2 e 3) vemos que as camadas de descongelamento são as correspondentes ao bloco5.
Como um lembrete, o resumo da convolução é
resumen(conv_base)==================================================================================# Layer Name Layer Input Shape Layer Output Shape Parameters==================================================================================0 input_6 (None, 150, 150, 3) (None, 150, 150, 3) 01 block1_conv1 (None, 150, 150, 3) (None, 150, 150, 64) 17922 block1_conv2 (None, 150, 150, 64) (None, 150, 150, 64) 369283 block1_pool (None, 150, 150, 64) (None, 75, 75, 64) 04 block2_conv1 (None, 75, 75, 64) (None, 75, 75, 128) 738565 block2_conv2 (None, 75, 75, 128) (None, 75, 75, 128) 1475846 block2_pool (None, 75, 75, 128) (None, 37, 37, 128) 07 block3_conv1 (None, 37, 37, 128) (None, 37, 37, 256) 2951688 block3_conv2 (None, 37, 37, 256) (None, 37, 37, 256) 5900809 block3_conv3 (None, 37, 37, 256) (None, 37, 37, 256) 59008010 block3_pool (None, 37, 37, 256) (None, 18, 18, 256) 011 block4_conv1 (None, 18, 18, 256) (None, 18, 18, 512) 118016012 block4_conv2 (None, 18, 18, 512) (None, 18, 18, 512) 235980813 block4_conv3 (None, 18, 18, 512) (None, 18, 18, 512) 235980814 block4_pool (None, 18, 18, 512) (None, 9, 9, 512) 015 block5_conv1 (None, 9, 9, 512) (None, 9, 9, 512) 235980816 block5_conv2 (None, 9, 9, 512) (None, 9, 9, 512) 235980817 block5_conv3 (None, 9, 9, 512) (None, 9, 9, 512) 235980818 block5_pool (None, 9, 9, 512) (None, 4, 4, 512) 0__________________________________________________________________________________Total Parameters : 14714688Total Trainable Parameters : 14714688Total No-Trainable Parameters : 0 vamos fazer O ajuste fino nas três últimas camadas convolucionárias: block5_conv1, block5_conv2 e block5_conv3.
É importante notar que as primeiras camadas codificam mais informações gerais para que não seja conveniente Renunciá-los se o propósito é reutilizar o conhecimento. Nós terminaríamos superando o modelo para pequenos nustras bd.
# Orden de las capas for layer in conv_base.layers: print(layer.name)input_6block1_conv1block1_conv2block1_poolblock2_conv1block2_conv2block2_poolblock3_conv1block3_conv2block3_conv3block3_poolblock4_conv1block4_conv2block4_conv3block4_poolblock5_conv1block5_conv2block5_conv3block5_poolconv_base.trainable = Trueset_trainable = Falsefor layer in conv_base.layers: if layer.name in : layer.trainable = True else: layer.trainable = False resumen(conv_base) ==================================================================================# Layer Name Layer Input Shape Layer Output Shape Parameters==================================================================================0 input_6 (None, 150, 150, 3) (None, 150, 150, 3) 01 block1_conv1 (None, 150, 150, 3) (None, 150, 150, 64) 17922 block1_conv2 (None, 150, 150, 64) (None, 150, 150, 64) 369283 block1_pool (None, 150, 150, 64) (None, 75, 75, 64) 04 block2_conv1 (None, 75, 75, 64) (None, 75, 75, 128) 738565 block2_conv2 (None, 75, 75, 128) (None, 75, 75, 128) 1475846 block2_pool (None, 75, 75, 128) (None, 37, 37, 128) 07 block3_conv1 (None, 37, 37, 128) (None, 37, 37, 256) 2951688 block3_conv2 (None, 37, 37, 256) (None, 37, 37, 256) 5900809 block3_conv3 (None, 37, 37, 256) (None, 37, 37, 256) 59008010 block3_pool (None, 37, 37, 256) (None, 18, 18, 256) 011 block4_conv1 (None, 18, 18, 256) (None, 18, 18, 512) 118016012 block4_conv2 (None, 18, 18, 512) (None, 18, 18, 512) 235980813 block4_conv3 (None, 18, 18, 512) (None, 18, 18, 512) 235980814 block4_pool (None, 18, 18, 512) (None, 9, 9, 512) 015 block5_conv1 (None, 9, 9, 512) (None, 9, 9, 512) 235980816 block5_conv2 (None, 9, 9, 512) (None, 9, 9, 512) 235980817 block5_conv3 (None, 9, 9, 512) (None, 9, 9, 512) 235980818 block5_pool (None, 9, 9, 512) (None, 4, 4, 512) 0__________________________________________________________________________________Total Parameters : 14714688Total Trainable Parameters : 7079424Total No-Trainable Parameters : 7635264 Nota que o conv_base tem treinamento e parampers não treináveis.
para treinamento fino Procuramos a compilação do modelo com um pequeno passo de passo para evitar grandes mudanças em pesos, uma vez que assumimos que é perto do ótimo e o ajuste não deve ser muito grande.
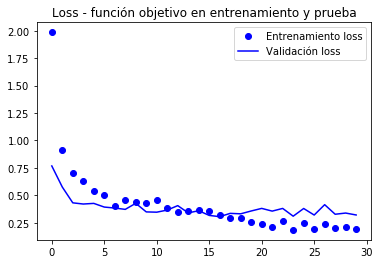
model.compile(loss='binary_crossentropy', optimizer=optimizers.RMSprop(lr=1e-5), metrics=)history = model.fit_generator( train_generator, steps_per_epoch=100, epochs=100, validation_data=validation_generator, validation_steps=50)Epoch 1/100100/100 - 10s 104ms/step - loss: 0.1938 - acc: 0.9645 - val_loss: 0.2769 - val_acc: 0.9580Epoch 2/100100/100 - 9s 94ms/step - loss: 0.2239 - acc: 0.9635 - val_loss: 0.2606 - val_acc: 0.9650... Epoch 100/100100/100 - 10s 97ms/step - loss: 0.0269 - acc: 0.9960 - val_loss: 0.3666 - val_acc: 0.9620model.save('cats_and_dogs_small_4.h5')gráficos de métricas registrados durante o treinamento
import matplotlib.pyplot as pltacc = history.historyval_acc = history.historyloss = history.historyval_loss = history.historyepochs = range(len(acc))plt.plot(epochs, acc, 'bo', label='Entrenamiento acc')plt.plot(epochs, val_acc, 'b', label='Validación acc')plt.title('Accuracy - exactitud de entrenamiento y validación')plt.legend()plt.figure()plt.plot(epochs, loss, 'bo', label='Entrenamiento loss')plt.plot(epochs, val_loss, 'b', label='Validación loss')plt.title('Loss - función objetivo en entrenamiento y prueba')plt.legend()plt.show() 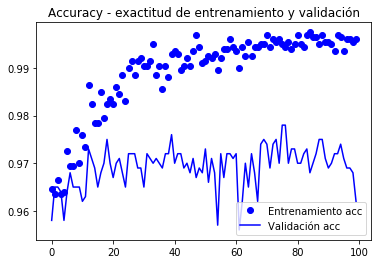
Como as curvas são muito barulhentas, É possível filtrá-los para apreciar melhor a tendência por meio de um filtro de baixa passagem, pode-se tentar
s ~ i = Σk = 0nwksi-k \ tilde s_i = \ sum_ {k = 0} ^ n w_k s_ {} s ~ i = k = 0σnwksi-k
Onde www são um Pesos CO n Σkwk = 1 \ sum_k w_k = 1σkwk = 1; Mas nós exigiremos um filtro bastante largo (grande NNN) para eliminar o ruído corretamente, em vez disso, tentamos a versão recursiva (como no livro na qual essas notas são baseadas)
i
s ~ i = αs ~ i -1+ (1-α) se \ tilde s_i = \ alpha \ tilde s_ {i-1} + (1- α) s_is ~ i = αs ~ i-1 + (1-α) se
Você usa os dados atualizados recentemente com um procedimento similar. Esses filtros recursivos podem ser expressos como não recursivos (substituindo os dados atualizados por sua fórmula). A vantagem do formulário recursivo é o compacto da expressão de atualização
def smooth_curve(points, factor=0.8): smoothed_points = for point in points: if smoothed_points: previous = smoothed_points smoothed_points.append(previous * factor + point * (1 - factor)) else: smoothed_points.append(point) return smoothed_pointsimport matplotlib.pyplot as pltacc = history.historyval_acc = history.historyloss = history.historyval_loss = history.historyepochs = range(len(acc))alpha = 0.9plt.plot(epochs, smooth_curve(acc, alpha), 'bo', label='Entrenamiento acc')plt.plot(epochs, smooth_curve(val_acc, alpha), 'b', label='Validación acc')plt.title('Accuracy - exactitud de entrenamiento y validación')plt.legend()plt.figure()plt.plot(epochs, smooth_curve(loss, alpha), 'bo', label='Entrenamiento loss')plt.plot(epochs, smooth_curve(val_loss,alpha), 'b', label='Validación loss')plt.title('Loss - función objetivo en entrenamiento y prueba')plt.legend()plt.show() 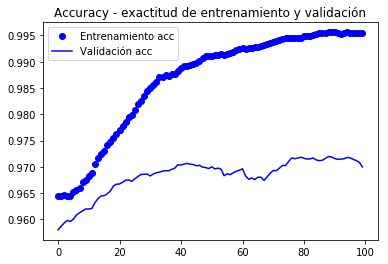
Nestes curvas, você pode apreciar melhor a tendência, podemos notar que foi uma melhoria de cerca de 1%.
In (Chocolet, 2018) A observação é feita de que a precisão está melhorando mesmo quando a perda não. Isso ocorre porque a perda é avaliada por um processo de soma de erro no vetor de saída, algo como:
σi∈epoch∥yi-y ^ i∥m \ sum_ {i \ in EPOCH} \ | Y_i – \ hat y_i \ | _mi∈epochς∥yi-y ^ i∥m
onde nós assumimos que a yyy está em uma codificação de um quente e m indica alguma métrica.Por outro lado, a precisão é calculada por meio de uma soma de erros de classificação:
σi∈poch1-δ (argmaxiyi-argmaxiy ^ i) \ sum_ {i \ em época } 1- Δ (τ \ rm \ max_i {\ hat y_i}) ∈Pochς1-δ (argimaxyi-argimaxy ^ i)
Agora avalie, finalmente e perecem, o conjunto de testes:
test_generator = test_datagen.flow_from_directory( test_dir, target_size=(150, 150), batch_size=20, class_mode='binary')test_loss, test_acc = model.evaluate_generator(test_generator, steps=50)print('test acc:', test_acc)Found 1000 images belonging to 2 classes.test acc: 0.9669999933242798* muito perto de 97%
na competição original de Kaggle, seria entre os melhores resultados (superiores), e que usamos apenas 2000 dados de treinamento vs. 20.000 na competição de Kaggle.
Resumo
- As redes convolucionais são o melhor modelo de redes neuronais para lidar com problemas de processamento de imagens e visão de computador.
-
O aumento de dados permite evitar a redução no banco de dados pequeno e aumentando com dados sintéticos do tamanho da amostra de treinamento
-
É possível Para usar os modelos pré-intenção no estágio de extração de recursos para lidar com pequenos bancos de dados.
-
O ajuste fino permite melhorar a interconexão do estágio predefinido com o estágio de STEADER, melhorando a desempenho a um baixo custo computacional.