Trasferimento della conoscenza (trasferimento della conoscenza)
Basato sull’esempio 5.3 di F Chollet, apprendimento profondo con Python, Ed Manning, 2018
Mariano Rivera
Versione 1.0
marzo 2019
import osos.environ="PCI_BUS_ID";os.environ="1"; import keraskeras.__version__Using TensorFlow backend.'2.2.4'VGG16: A Convolutions Network PRESET
Una strategia per la gestione di reti neurali profonde è utilizzare le reti precedentemente pre-accentenze con banche dati di grandi dimensioni e adattarle al problema del nostro interesse.
A tal fine è necessario che la rete pre-intenzione sia stata addestrata a risolvere un problema di natura più generale, da cui il nostro problema può essere considerato un caso particolare. Ad esempio, per il caso di classificazione di cani e gatti, possiamo utilizzare una rete formata per classificare più lezioni come il cosiddetto VGG16 (Simonyan e Zisserman, 2015). Le ragioni che utilizziamo VGG16 sono le seguenti
-
ha un’architettura facile da comprendere e, se applicabile, da implementare.
-
Raggiungere un risultato eccellente nella concorrenza ImagEnet (ILSVRC-2014), tra il 96% e il 97%.
-
contiene relativamente pochi strati contorzionali: 13 strati convoluzionari e 3 fitti, Quindi, nel suo nome includere 16.
-
la rete (modello e pesos addestrati) questo diponibile in Kera
( Simonyan e Zisserman, 2015) K. Simonyan e A. Zisserman, reti di convoluzione molto profonda per riconoscimento di immagini su larga scala, 3rd ICLR 2015.
reti diponibili in keras che sono stati addestrati nel BD Imagenet sono
- xception
- InceptionV3
- vgg16
- vgg19
- mobilenet
La rete VGG19 è una variante con più strati di calcolo rispetto al VGG16, quindi più pesante rispetto alla memorizzata in materia di memoria e requisiti di calcolo.
Co. MO Vediamo, poiché VGG16 è stato addestrato a risolvere il problema di classifica di 1000 rivestire in Imagenet, deve nei suoi pesi codificare le informazioni per estrarre caratteristiche di classis molto diverse da rappresentato nelle più di 1,4 milioni di fotografie Imagenet. Tra quelle classi ci sono varietà di animali molto diverse, in ambienti molto diversi. Pertanto, VGG16 è un ottimo candidato per essere particolarmente specificato al problema della classificazione binaria dei cani e dei gatti.
Note che ci sono prestazioni più moderne, migliori, ma VGG16 servirà molto bene per il nostro scopo. Come abbiamo visto negli esempi precedenti, le reti contorzionali per la classificazione seguono una struttura a due blocchi:
-
fase degli strati convertiti per l’estrazione delle funzionalità
-
Fase decisionale basata sulla strato densa.
vgg16 Questa architettura continua fedelmente. Visualizza Siginete figure

L’uso di VGG16 precedentemente formato con BD Imagenet ci consente di presumere che la sua fase di estrazione delle funzioni, In effetti, le relazioni eperate che rendono gli oggetti distintivi e l’idoneità dell’immagine, ci fa assumere che queste relazioni spaziali siano sufficientemente generiche per essere in grado di codificare caratteristiche distintive dei cani e dei gatti.
Andremo passo dopo Passaggio, abbiamo caricato per la prima volta la rete VGG16 nel pacchetto keras.applications.
Accesso ai componenti di una rete di convultura PretRended
Vediamo come Carica un modello preimpostato e poiché possiamo accedere ai suoi componenti. Come illustrazione, definiamo la nostra versione della funzione summary dei modelli Keras. Con questo mostriamo come accedere ai nomi degli strati, il loro numero di parametri, ecc.
quindi caricare il modello VGG16 con i seguenti parametri:
-
pesi indica che i pesi verranno utilizzati per inizializzare il modello
-
includ_top indica se è caricata la rete completa (estrazione delle caratteristiche e Stadio della decisione) o solo lo stadio di estrazione dei soggetti
-
ingresso_shape la forma delle immagini da elaborare (opzionale, poiché la rete è possibile elaborare qualsiasi dimensione dell’immagine)
from keras.applications import VGG16vgg16 = VGG16(weights='imagenet', include_top=True, input_shape=(224, 224, 3))resumen(vgg16)
sono circa 139 milioni di parametri. Ha davvero consumato il tempo per scaricare il modello completo (è fatto solo per la prima volta che viene richiamata la funzione VGG16. Notezziamo che, fortunatamente, molti dei parametri (come il 90%) corrispondono alla fase decisionale. L’estrazione del tratto Stage (illustrato nella figura seguente) ha meno parametri.

(immagine presa dalla rete, utilizzata in diversi blog, come nell’illustrazione VGG16)
Per evitare di caricare gli strati che non utilizzeremo possiamo richiamare il metodo con il parametro include_top=False e per la dimensione specifica che abbiamo utilizzato (150 × 150150 \ volte 150150 × 150 pixel)
if vgg16 != None: del vgg16 from keras.applications import VGG16conv_base = VGG16(weights='imagenet', include_top=False, input_shape=(150, 150, 3)) resumen(conv_base) ==================================================================================# Layer Name Layer Input Shape Layer Output Shape Parameters==================================================================================0 input_6 (None, 150, 150, 3) (None, 150, 150, 3) 01 block1_conv1 (None, 150, 150, 3) (None, 150, 150, 64) 17922 block1_conv2 (None, 150, 150, 64) (None, 150, 150, 64) 369283 block1_pool (None, 150, 150, 64) (None, 75, 75, 64) 04 block2_conv1 (None, 75, 75, 64) (None, 75, 75, 128) 738565 block2_conv2 (None, 75, 75, 128) (None, 75, 75, 128) 1475846 block2_pool (None, 75, 75, 128) (None, 37, 37, 128) 07 block3_conv1 (None, 37, 37, 128) (None, 37, 37, 256) 2951688 block3_conv2 (None, 37, 37, 256) (None, 37, 37, 256) 5900809 block3_conv3 (None, 37, 37, 256) (None, 37, 37, 256) 59008010 block3_pool (None, 37, 37, 256) (None, 18, 18, 256) 011 block4_conv1 (None, 18, 18, 256) (None, 18, 18, 512) 118016012 block4_conv2 (None, 18, 18, 512) (None, 18, 18, 512) 235980813 block4_conv3 (None, 18, 18, 512) (None, 18, 18, 512) 235980814 block4_pool (None, 18, 18, 512) (None, 9, 9, 512) 015 block5_conv1 (None, 9, 9, 512) (None, 9, 9, 512) 235980816 block5_conv2 (None, 9, 9, 512) (None, 9, 9, 512) 235980817 block5_conv3 (None, 9, 9, 512) (None, 9, 9, 512) 235980818 block5_pool (None, 9, 9, 512) (None, 4, 4, 512) 0__________________________________________________________________________________Total Parameters : 14714688Total Trainable Parameters : 14714688Total No-Trainable Parameters : 0sono “solo” poco meno di 15 milioni di parametri, una sostanziale riduzione rispetto al VGG16 completo rete.
Vediamo il riepilogo della rete Keras
#conv_base.summary() L’uscita finale del modello di base caricata (conv_base) I .
Rete pre-immessa in pre-immesso come caratteristiche di estrattore offline
La prima strategia che useremo per riutilizzare la conoscenza memorizzata (acquisita) da una rete classificante e particolarmente conto al nostro sarà nel considerare l’estrazione di tratti indipendenti della classificazione ione È un approccio di tipo cupo (al contrario del profondo). Cioè, passeremo le immagini alla rete di convolve di base (conv_base) e memorizza le caratteristiche in memoria o disco (che è computazionalmente efficiente) e quindi feed con tali funzioni un classificatore. Questo è illustrato nella figura seguente.

per generare la codifica (pizzo o incorporamento) di immagini e gatti Utilizzerà un generatore
È importante se utilizziamo VGG16 preprocesso i dati (immagini) per normalizzarli con la stessa procedura utilizzata per addestrare la rete originale. In questo caso, non è quello di salvarli all’intervallo, ma per sottrarre la media di ciascun canale di colore
import osimport numpy as npfrom tqdm import tqdmfrom keras.applications.imagenet_utils import preprocess_input#from tqdm import tqdm_notebook as tqdmfrom keras.preprocessing.image import ImageDataGeneratorbase_dir = '/home/mariano/Data/dogs_vs_cats_small'#base_dir = '/home/mariano/Documents/deep/kaggle/dogs_vs_cats_small'train_dir = os.path.join(base_dir, 'train')validation_dir = os.path.join(base_dir, 'validation')test_dir = os.path.join(base_dir, 'test')datagen = ImageDataGenerator(#rescale=1./255) preprocessing_function=preprocess_input)batch_size = 20def extract_features(directory, sample_count): ''' Codificador de imagenes mediante conv_base en rasgos para posteriormente usarlos como datos para una red clasificadora densa parámetros directory directorio con con los subdirectorios que definen clases sample_count número de muestras a generar resultados conjunto de características y etiquetas ''' # memoria para tensores con datos y etiquetas features = np.zeros(shape=(sample_count, 4, 4, 512)) labels = np.zeros(shape=(sample_count)) # instanciación del generador a partir del directorio donde estan las clases generator = datagen.flow_from_directory(directory, target_size = (150, 150), batch_size = batch_size, class_mode = 'binary') rango = list(range(int(sample_count/batch_size))) i = 0 with tqdm(total=len(rango)) as pbar: for inputs_batch, labels_batch in tqdm(generator): # características predichas (codificadas) por la subred base # para las imágenes generadas (aumentadas) en lote features_batch = conv_base.predict(inputs_batch) # datos y etiquetas features = features_batch labels = labels_batch i += 1 if i * batch_size >= sample_count: # La ejecucion del generador debe terminarse explícitamente después # usar todas la imágenes break pbar.update(1) return features, labelsSet di tratti dati per la formazione, convalida e test
train_features, train_labels = extract_features(train_dir, 2000)validation_features, validation_labels = extract_features(validation_dir, 1000)test_features, test_labels = extract_features(test_dir, 1000) 0%| | 0/100 0%| | 0/100 3%|▎ | 3/100 ... 99%|█████████▉| 99/100 2%|▏ | 1/50 ... 98%|█████████▊| 49/50 2%|▏ | 1/50 ... 98%|█████████▊| 49/50 )import timetstart = time.time()history = model.fit(train_features, train_labels, epochs = 30, batch_size = 20, validation_data = (validation_features, validation_labels), verbose = 2)print('seconds=', time.time()-tstart)Train on 2000 samples, validate on 1000 samplesEpoch 1/30 - 1s - loss: 3.3298 - acc: 0.7205 - val_loss: 1.0112 - val_acc: 0.8950...Epoch 30/30 - 0s - loss: 0.0800 - acc: 0.9905 - val_loss: 0.3714 - val_acc: 0.9630seconds= 14.222734451293945 L’allenamento è molto veloce Dato che la rete di classificazione è composta solo di due strati Dense.
le curve del valore della funzione di destinazione e precisione (accuracy) Sono mostrati sotto.
import matplotlib.pyplot as pltacc = history.historyval_acc = history.historyloss = history.historyval_loss = history.historyepochs = range(len(acc))plt.plot(epochs, acc, 'bo', label='Entrenamiento acc')plt.plot(epochs, val_acc, 'b', label='Validación acc')plt.title('Accuracy - exactitud de entrenamiento y validación')plt.legend()plt.figure()plt.plot(epochs, loss, 'bo', label='Entrenamiento loss')plt.plot(epochs, val_loss, 'b', label='Validación loss')plt.title('Loss - función objetivo en entrenamiento y prueba')plt.legend()plt.show() 

Vallazione raggiunge la precisione del 90%, molto meglio del modello formato con l’aumento dei dati e il BD Paquea che ha raggiunto l’86%.
La curva di precisione illustra molto presto che inizi ad avere un sovraccarico (overfitting). È perché non usiamo l’aumentazione.
Per implementare l’aumento che dobbiamo far effettuare l’estrazione dei tratti contemporaneamente in cui classifichiamo, come modello completo. Bene, in memoria o disco sarebbe poco pratico di memorizzare i dati aumentati per la sua classificazione successiva. Questo è spiegato di seguito.
Rete Knowledge Transfer Grounders a nuovi problemi
il modello conv_base come strato di estrazione di rimozione
Se assumiamo che la fase contorta del VGG16 estrae le caratteristiche generali, sarà quella parte che possiamo riutilizzare. Le caratteristiche estratte devono essere passate ad un nuovo classificatore binario che dobbiamo implementare e addestrare la professione ex. Questo processo è Mustra nella figura seguente

come illustra la figura,
-
Riutiliamo solo la fase contorta della rete.
-
Definiamo una nuova fase di classificazione in base al nostro problema.
-
Dal momento che abbiamo, relativamente, pochi dati di formazione, impostare la sottorete dell’estrazione delle funzionalità (congelare i loro pesi) per impedire che vengano modificati in formazione.
-
Forniamo i pesi “lavorabili”, quelli della fase di rango che fanno i nostri dati attraverso l’intera rete.
Utilizzeremo i generatori di dati per fare una formazione con i generatori (fit_generator), come nell’esempio della sezione precedente.
in keras tutto sono livelli (strati), quindi useremo il modello conv_base Come il primo strato della rete, un livello che calcola le funzioni.
quindi aggiungere al nuovo modello di livelli sequenziali classifica Dense Doras.
Questa tecnica anche se semplice per implementare vergogna che ogni aumento dell’immagine è passata attraverso la rete conv_base e poi attraverso il sorter. Ciò causa i calcoli ora più costosi e non è possibile eseguirli in CPU, abbiamo bisogno di una GPU.
model.reset_states()from keras import modelsfrom keras import layersmodel = models.Sequential()model.add(conv_base) # modelo base agradado como una capa!model.add(layers.Flatten())model.add(layers.Dense(256, activation='relu'))#model.add(layers.Dropout(0.3)) # a vermodel.add(layers.Dense(1, activation='sigmoid'))Questo è ciò che sembra il nostro modello ora:
#model.summary()resumen(model)==================================================================================# Layer Name Layer Input Shape Layer Output Shape Parameters==================================================================================0 vgg16 (None, 150, 150, 3) (None, 4, 4, 512) 147146881 flatten_1 (None, 4, 4, 512) (None, 8192) 02 dense_3 (None, 8192) (None, 256) 20974083 dense_4 (None, 256) (None, 1) 257__________________________________________________________________________________Total Parameters : 16812353Total Trainable Parameters : 16812353Total No-Trainable Parameters : 0la rete di convultura della base VGG16 milioni di parametri, che è molto grande. Il classificatore sulla fermata aggiunge altri 2 milioni di arresti.
Prima della formazione “Frigeriamo” l’estrazione della rete delle funzionalità poiché abbiamo alcuni dati e vogliamo sfruttare la “conoscenza” memorizzata nella sottorete di base VGG16 che è stata addestrata con molte classi e dovrebbe essere un gran’estrattore generale delle caratteristiche.
Ciò raggiunto segnando i pesi di “The Layer” conv_base come non allenamento:
print('Número de pesos (matrices) entrenables antes de congelar conv_base : ', len(model.trainable_weights))Número de pesos (matrices) entrenables antes de congelar conv_base : 30conv_base.trainable = Falseprint('Número de pesos (matrices) entrenables después de congelar conv_base : ', len(model.trainable_weights))Número de pesos (matrices) entrenables después de congelar conv_base : 4==================================================================================# Layer Name Layer Input Shape Layer Output Shape Parameters==================================================================================0 vgg16 (None, 150, 150, 3) (None, 4, 4, 512) 147146881 flatten_1 (None, 4, 4, 512) (None, 8192) 02 dense_3 (None, 8192) (None, 256) 20974083 dense_4 (None, 256) (None, 1) 257__________________________________________________________________________________Total Parameters : 16812353Total Trainable Parameters : 2097665Total No-Trainable Parameters : 14714688Il numero di matrici supera gli strati perché ogni strato può avere una matrice di peso www e un vettore di bias bbb bbb.
Per effettuare il congelamento dei dati dobbiamo compilare il modello e quindi definire i parametri per il generatore.
from keras.preprocessing.image import ImageDataGeneratorfrom keras import modelsfrom keras import layersfrom keras import optimizerstrain_datagen = ImageDataGenerator(#rescale = 1./255, preprocessing_function=preprocess_input, rotation_range = 40, width_shift_range = 0.2, height_shift_range= 0.2, shear_range = 0.2, zoom_range = 0.2, horizontal_flip = True, fill_mode = 'constant', #'nearest') cval = 0)# La validación no se aumenta!test_datagen = ImageDataGenerator(#rescale=1./255) preprocessing_function=preprocess_input)train_generator = train_datagen.flow_from_directory( train_dir, # directorio con datos de entrenamiento target_size= (150, 150), # tamaño de la imágenes batch_size = 20, shuffle = True, class_mode = 'binary') # para clasificación binariavalidation_generator = test_datagen.flow_from_directory( validation_dir, target_size=(150, 150), batch_size=20, class_mode='binary')model.compile(loss='binary_crossentropy', optimizer=keras.optimizers.Nadam(lr=2e-5), #optimizers.RMSprop(lr=2e-5), metrics=)#model.reset_states()import timetstart = time.time()history = model.fit_generator(train_generator, steps_per_epoch = 100, epochs = 30, validation_data = validation_generator, validation_steps= 50, verbose = 2)print('seconds=', time.time()-tstart)Found 2000 images belonging to 2 classes.Found 1000 images belonging to 2 classes.Epoch 1/30 - 10s - loss: 1.9860 - acc: 0.7660 - val_loss: 0.7680 - val_acc: 0.9040Epoch 2/30 - 9s - loss: 0.9115 - acc: 0.8815 - val_loss: 0.5760 - val_acc: 0.9210...Epoch 30/30 - 9s - loss: 0.1956 - acc: 0.9640 - val_loss: 0.3213 - val_acc: 0.9660seconds= 281.5276675224304model.save('cats_and_dogs_small_3.h5')Grafico grafico Il comportamento delle metriche registrate durante il nazione
import matplotlib.pyplot as pltacc = history.historyval_acc = history.historyloss = history.historyval_loss = history.historyepochs = range(len(acc))plt.plot(epochs, acc, 'bo', label='Entrenamiento acc')plt.plot(epochs, val_acc, 'b', label='Validación acc')plt.title('Accuracy - exactitud de entrenamiento y validación')plt.legend()plt.figure()plt.plot(epochs, loss, 'bo', label='Entrenamiento loss')plt.plot(epochs, val_loss, 'b', label='Validación loss')plt.title('Loss - función objetivo en entrenamiento y prueba')plt.legend()plt.show() 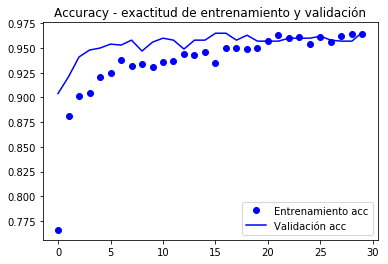
Secondo l’autore del libro (Ballotto), viene raggiunta una precisione di quasi il 96,5%.
Regolazione fine
Un’altra strategia ampiamente utilizzata nel riutilizzo di raffinatezza è la regolazione fine (fine-tuning), che coerente che, una volta un livello di classificazione con prerenetranda, è stato addestrato, scongelare il Ultimi livelli della base contorica per consentire ai loro pesi di adattarsi meglio al livello di classificazione. Raggiungere una migliore integrazione tra la base (addestrata per un problema diverso) e la classificazione.
I passaggi della formazione fine sono:
- Aggiungi a una base convolutiva generale. Classificazione finale.
- Blocca la base contorta.
- Allenando lo stadio di smistamento.
- scongelare gli ultimi livelli della base contorica.
- Treno Sorting Stage e Ultimi livelli del convoluzionario insieme.
parte del precedente modello precedente (passaggi 1,2 e 3) vediamo che gli strati da scongelare sono quelli corrispondenti a Block5.
Come promemoria Il riassunto della convoluzione è
resumen(conv_base)==================================================================================# Layer Name Layer Input Shape Layer Output Shape Parameters==================================================================================0 input_6 (None, 150, 150, 3) (None, 150, 150, 3) 01 block1_conv1 (None, 150, 150, 3) (None, 150, 150, 64) 17922 block1_conv2 (None, 150, 150, 64) (None, 150, 150, 64) 369283 block1_pool (None, 150, 150, 64) (None, 75, 75, 64) 04 block2_conv1 (None, 75, 75, 64) (None, 75, 75, 128) 738565 block2_conv2 (None, 75, 75, 128) (None, 75, 75, 128) 1475846 block2_pool (None, 75, 75, 128) (None, 37, 37, 128) 07 block3_conv1 (None, 37, 37, 128) (None, 37, 37, 256) 2951688 block3_conv2 (None, 37, 37, 256) (None, 37, 37, 256) 5900809 block3_conv3 (None, 37, 37, 256) (None, 37, 37, 256) 59008010 block3_pool (None, 37, 37, 256) (None, 18, 18, 256) 011 block4_conv1 (None, 18, 18, 256) (None, 18, 18, 512) 118016012 block4_conv2 (None, 18, 18, 512) (None, 18, 18, 512) 235980813 block4_conv3 (None, 18, 18, 512) (None, 18, 18, 512) 235980814 block4_pool (None, 18, 18, 512) (None, 9, 9, 512) 015 block5_conv1 (None, 9, 9, 512) (None, 9, 9, 512) 235980816 block5_conv2 (None, 9, 9, 512) (None, 9, 9, 512) 235980817 block5_conv3 (None, 9, 9, 512) (None, 9, 9, 512) 235980818 block5_pool (None, 9, 9, 512) (None, 4, 4, 512) 0__________________________________________________________________________________Total Parameters : 14714688Total Trainable Parameters : 14714688Total No-Trainable Parameters : 0 faremo La regolazione fine sugli ultimi tre strati convoluzionari: block5_conv1, block5_conv2 e block5_conv3.
è importante notare che i primi livelli del codice sono più informazioni generali, quindi non è conveniente Rendiscili se lo scopo è di riutilizzare la conoscenza. Finiremmo il sopravvalutare il modello a piccoli BD Nustras.
# Orden de las capas for layer in conv_base.layers: print(layer.name)input_6block1_conv1block1_conv2block1_poolblock2_conv1block2_conv2block2_poolblock3_conv1block3_conv2block3_conv3block3_poolblock4_conv1block4_conv2block4_conv3block4_poolblock5_conv1block5_conv2block5_conv3block5_poolconv_base.trainable = Trueset_trainable = Falsefor layer in conv_base.layers: if layer.name in : layer.trainable = True else: layer.trainable = False resumen(conv_base) ==================================================================================# Layer Name Layer Input Shape Layer Output Shape Parameters==================================================================================0 input_6 (None, 150, 150, 3) (None, 150, 150, 3) 01 block1_conv1 (None, 150, 150, 3) (None, 150, 150, 64) 17922 block1_conv2 (None, 150, 150, 64) (None, 150, 150, 64) 369283 block1_pool (None, 150, 150, 64) (None, 75, 75, 64) 04 block2_conv1 (None, 75, 75, 64) (None, 75, 75, 128) 738565 block2_conv2 (None, 75, 75, 128) (None, 75, 75, 128) 1475846 block2_pool (None, 75, 75, 128) (None, 37, 37, 128) 07 block3_conv1 (None, 37, 37, 128) (None, 37, 37, 256) 2951688 block3_conv2 (None, 37, 37, 256) (None, 37, 37, 256) 5900809 block3_conv3 (None, 37, 37, 256) (None, 37, 37, 256) 59008010 block3_pool (None, 37, 37, 256) (None, 18, 18, 256) 011 block4_conv1 (None, 18, 18, 256) (None, 18, 18, 512) 118016012 block4_conv2 (None, 18, 18, 512) (None, 18, 18, 512) 235980813 block4_conv3 (None, 18, 18, 512) (None, 18, 18, 512) 235980814 block4_pool (None, 18, 18, 512) (None, 9, 9, 512) 015 block5_conv1 (None, 9, 9, 512) (None, 9, 9, 512) 235980816 block5_conv2 (None, 9, 9, 512) (None, 9, 9, 512) 235980817 block5_conv3 (None, 9, 9, 512) (None, 9, 9, 512) 235980818 block5_pool (None, 9, 9, 512) (None, 4, 4, 512) 0__________________________________________________________________________________Total Parameters : 14714688Total Trainable Parameters : 7079424Total No-Trainable Parameters : 7635264 Nota ora che conv_base ha formazione e parampitori non addestrabili.
per un allenamento fine Procediamo a compilare il modello con una piccola dimensione del passo per evitare grandi cambiamenti nei pesi, dal momento che assumiamo che sia vicino all’ottimale e la regolazione non dovrebbe essere molto grande.
model.compile(loss='binary_crossentropy', optimizer=optimizers.RMSprop(lr=1e-5), metrics=)history = model.fit_generator( train_generator, steps_per_epoch=100, epochs=100, validation_data=validation_generator, validation_steps=50)Epoch 1/100100/100 - 10s 104ms/step - loss: 0.1938 - acc: 0.9645 - val_loss: 0.2769 - val_acc: 0.9580Epoch 2/100100/100 - 9s 94ms/step - loss: 0.2239 - acc: 0.9635 - val_loss: 0.2606 - val_acc: 0.9650... Epoch 100/100100/100 - 10s 97ms/step - loss: 0.0269 - acc: 0.9960 - val_loss: 0.3666 - val_acc: 0.9620model.save('cats_and_dogs_small_4.h5')Metrics Graphs registrati durante l’allenamento
import matplotlib.pyplot as pltacc = history.historyval_acc = history.historyloss = history.historyval_loss = history.historyepochs = range(len(acc))plt.plot(epochs, acc, 'bo', label='Entrenamiento acc')plt.plot(epochs, val_acc, 'b', label='Validación acc')plt.title('Accuracy - exactitud de entrenamiento y validación')plt.legend()plt.figure()plt.plot(epochs, loss, 'bo', label='Entrenamiento loss')plt.plot(epochs, val_loss, 'b', label='Validación loss')plt.title('Loss - función objetivo en entrenamiento y prueba')plt.legend()plt.show() 

Poiché le curve sono molto rumorose, È possibile filtrarli per apprezzare meglio la tendenza per mezzo di un filtro passa-basso, si potrebbe provare
s ~ i = σk = 0nwksi-k \ tilde s_i = \ sum_ {k = 0} ^ n w_k s_ {ik} s ~ i = k = 0σnwksi-k
dove www è un pesos co n σkwk = 1 \ sum_k w_k = 1σkwk = 1; Ma richiederemo un filtro abbastanza ampio (grande NNN) per eliminare correttamente il rumore, invece, proviamo la versione ricorsiva (come nel libro su cui queste note sono basate)
I
S ~ i = αs ~ i -1+ (1-α) se \ tilde s_i = \ alfa \ tilde s_ {i-1} + (1- α) s_is ~ i = αs ~ i-1 + (1-α) se
che usi i dati aggiornati di recente con una procedura simile. Questi filtri ricorsivi possono essere espressi come non ricorsivi (sostituendo i dati aggiornati dalla sua formula). Il vantaggio della forma ricorsiva è il compatto di aggiornamento di espressione
def smooth_curve(points, factor=0.8): smoothed_points = for point in points: if smoothed_points: previous = smoothed_points smoothed_points.append(previous * factor + point * (1 - factor)) else: smoothed_points.append(point) return smoothed_pointsimport matplotlib.pyplot as pltacc = history.historyval_acc = history.historyloss = history.historyval_loss = history.historyepochs = range(len(acc))alpha = 0.9plt.plot(epochs, smooth_curve(acc, alpha), 'bo', label='Entrenamiento acc')plt.plot(epochs, smooth_curve(val_acc, alpha), 'b', label='Validación acc')plt.title('Accuracy - exactitud de entrenamiento y validación')plt.legend()plt.figure()plt.plot(epochs, smooth_curve(loss, alpha), 'bo', label='Entrenamiento loss')plt.plot(epochs, smooth_curve(val_loss,alpha), 'b', label='Validación loss')plt.title('Loss - función objetivo en entrenamiento y prueba')plt.legend()plt.show() 

In queste curve è possibile apprezzare meglio la tendenza, possiamo notare che è stato un miglioramento di circa l’1%.
In (Bellot, 2018) L’osservazione è resa che la precisione sta migliorando anche quando la perdita no. Questo perché la perdita è valutata da un processo di somma di errore nel vettore di output, qualcosa del genere come:
σi∈epoch∥yi-y ^ i∥m \ sum_ {i \ in Epoch} \ | | Y_i – \ cappello y_i \ | _mi∈epocharΣ∥yi-y ^ i∥m
Dove assumiamo che Yyy sia in una codifica a caldo e m indica alcune metriche.D’altra parte, l’accuratezza è calcolata mediante una somma di errori di classificazione:
σi∈epoch1-Δ (argmaxiyi-argmaxiy ^ i) \ sum_ {i \ in epoca } 1- Δ (τ \ rm \ max_i {\ cappello y_i}) ∈epocharΣ1-Δ (Argimaxyi-argimaxy ^ i)
Ora valuta, infine e perire, il set di test:
test_generator = test_datagen.flow_from_directory( test_dir, target_size=(150, 150), batch_size=20, class_mode='binary')test_loss, test_acc = model.evaluate_generator(test_generator, steps=50)print('test acc:', test_acc)Found 1000 images belonging to 2 classes.test acc: 0.9669999933242798* Molto vicino al 97%
Nella concorrenza originale di Kaggle, sarebbe tra i I migliori (principali) risultati e che utilizziamo solo i dati di formazione 2000 contro 20.000 nella competizione Kaglegle.
Riepilogo
-
Le reti contorzionali sono il miglior modello di reti neuronali per gestire il trattamento delle immagini e problemi di visione informatica.
-
L’aumentazione dei dati consente di evitare di sovrascrivere il piccolo database e aumentare con i dati sintetici la dimensione del campione di allenamento
-
è possibile Per utilizzare i modelli pre-intenti nella fase di estrazione caratteristica per gestire piccoli database.
-
La regolazione fine consente di migliorare l’interconnessione dello stadio preimpostato con lo stadio dello steader, migliorando il generale prestazioni a basso costo computazionale.