Transferencia de coñecemento (transferencia de coñecemento)
baseado no exemplo 5.3 de F Chollet, aprendizaxe profunda con Python, Ed Manning, 2018
Mariano Rivera
versión 1.0
marzo de 2019
import osos.environ="PCI_BUS_ID";os.environ="1"; import keraskeras.__version__Using TensorFlow backend.'2.2.4'VGG16: unha estratexia predefinida de rede
Unha estratexia para tratar en redes neuronais profundas é usar redes previamente previamente atentas con grandes bases de datos e adaptalas ao problema do noso interese.
Para este propósito é necesario que a rede de pre-intención sexa adestrada para resolver un problema de carácter máis xeral, a partir do cal o noso problema pode considerarse un caso particular. Por exemplo, para o caso de clasificar cans e gatos, podemos usar unha rede adestrada para clasificar máis clases como o chamado VGG16 (Simonyan e Zisserman, 2015). Os motivos que usamos VGG16 son os seguintes
-
ten unha arquitectura de fácil comprensión e, se procede, para implementar.
-
lograr un excelente resultado na competencia ImageNet (ILSVRC-2014), entre o 96% e o 97%.
-
conteñen relativamente poucas capas convolucionais: 13 capas convolucionarias e 3 densas, Por iso, no seu nome inclúen 16.
-
a rede (modelo e pesos adestrado) este diponible en kera
( Simonyan e zisserman, 2015) K. simonyan e A. zisserman, redes de convolución moi profunda para recoñecemento de imaxes a grande escala, 3ª ICLR 2015.
Redes diponibles en Keras que foron adestrados no BD Imagenet son
- Xestor
- vgg16
- vgg19
- MobileNet
A rede VGG19 é unha variante con máis capas de cálculo que o VGG16, polo tanto, máis pesado que almacenado en requisitos de memoria e informática.
Co. Mo Vemos, pois VGG16 foi adestrado para resolver a clasificación problema de 1000 vestida con IMAGEnet, debe, de información pesos codificar a recursos extracto de classis moi diferente da representada nas máis de 1,4 millóns de fotografías IMAGEnet. Entre esas clases hai variedades de animais moi diferentes, en ambientes moi diferentes. Polo tanto, VGG16 é un candidato moi bo para participar no problema da clasificación binaria de cans e gatos.
Observamos que hai máis moderno, mellor rendemento, pero VGG16 servirá moi ben para o noso propósito. Como vimos nos exemplos anteriores, as redes convolucionais para a clasificación seguen unha estrutura de dous bloques:
-
Paso de capas convertidas para a extracción de funcións
-
Paso de decisión baseada en capa densa.
VGG16 Esta arquitectura continúa fielmente. Ver Siginete Figura

Usar VGG16 previamente adestrado co BD ImageNet permítenos supoñer que a súa etapa de extracción de características, Efectivamente, as relacións epaceiales que fan que os obxectos distinguibles ea auxedidez de Imagenet fagan que as supoñen que estas relacións espaciais son suficientemente xenéricas para poder codificar características distintivas de cans e gatos.
Imos paso por paso, primeiro cargamos a rede VGG16 no paquete keras.applications.
Acceso aos compoñentes dunha rede de convocatoria pretratada
Vexamos como Cargue un modelo predefinido e como podemos acceder aos seus compoñentes. Como ilustración, definimos a nosa versión da función summary dos modelos de Keras. Con iso, amosamos como o acceso aos nomes das capas, o número de parámetros, etc.
def resumen(model=None): ''' ''' header = '{:4} {:16} {:24} {:24} {:10}'.format('#', 'Layer Name','Layer Input Shape','Layer Output Shape','Parameters' ) print('='*(len(header))) print(header) print('='*(len(header))) count=0 count_trainable=0 for i, layer in enumerate(model.layers): count_trainable += layer.count_params() if layer.trainable else 0 input_shape = '{}'.format(layer.input_shape) output_shape = '{}'.format(layer.output_shape) str = '{:<4d} {:16} {:24} {:24} {:10}'.format(i,layer.name, input_shape, output_shape, layer.count_params()) print(str) count += layer.count_params() print('_'*(len(header))) print('Total Parameters : ', count) print('Total Trainable Parameters : ', count_trainable) print('Total No-Trainable Parameters : ', count-count_trainable) vgg16=None, logo cargar o modelo VGG16 cos seguintes parámetros:
-
Pesos indican que os pesos usaranse para inicializar o modelo
-
incluír_top indica se a rede completa está cargada (a extracción de características e Etapa de decisión) ou só a etapa de extracción dos suxeitos
-
Input_shape a forma das imaxes a procesar (opcional, xa que a rede pode procesar calquera dimensión de imaxe)
from keras.applications import VGG16vgg16 = VGG16(weights='imagenet', include_top=True, input_shape=(224, 224, 3))resumen(vgg16)==================================================================================# Layer Name Layer Input Shape Layer Output Shape Parameters==================================================================================0 input_5 (None, 224, 224, 3) (None, 224, 224, 3) 01 block1_conv1 (None, 224, 224, 3) (None, 224, 224, 64) 17922 block1_conv2 (None, 224, 224, 64) (None, 224, 224, 64) 369283 block1_pool (None, 224, 224, 64) (None, 112, 112, 64) 04 block2_conv1 (None, 112, 112, 64) (None, 112, 112, 128) 738565 block2_conv2 (None, 112, 112, 128) (None, 112, 112, 128) 1475846 block2_pool (None, 112, 112, 128) (None, 56, 56, 128) 07 block3_conv1 (None, 56, 56, 128) (None, 56, 56, 256) 2951688 block3_conv2 (None, 56, 56, 256) (None, 56, 56, 256) 5900809 block3_conv3 (None, 56, 56, 256) (None, 56, 56, 256) 59008010 block3_pool (None, 56, 56, 256) (None, 28, 28, 256) 011 block4_conv1 (None, 28, 28, 256) (None, 28, 28, 512) 118016012 block4_conv2 (None, 28, 28, 512) (None, 28, 28, 512) 235980813 block4_conv3 (None, 28, 28, 512) (None, 28, 28, 512) 235980814 block4_pool (None, 28, 28, 512) (None, 14, 14, 512) 015 block5_conv1 (None, 14, 14, 512) (None, 14, 14, 512) 235980816 block5_conv2 (None, 14, 14, 512) (None, 14, 14, 512) 235980817 block5_conv3 (None, 14, 14, 512) (None, 14, 14, 512) 235980818 block5_pool (None, 14, 14, 512) (None, 7, 7, 512) 019 flatten (None, 7, 7, 512) (None, 25088) 020 fc1 (None, 25088) (None, 4096) 10276454421 fc2 (None, 4096) (None, 4096) 1678131222 predictions (None, 4096) (None, 1000) 4097000__________________________________________________________________________________Total Parameters : 138357544Total Trainable Parameters : 138357544Total No-Trainable Parameters : 0
son preto de 139 millóns de parámetros. Realmente consumiu tempo para descargar o modelo completo (só se fai por primeira vez que a función VGG16 está invocada. Observamos que, afortunadamente, moitos dos parámetros (como o 90%) corresponden ao paso de decisión. A extracción de trazos O escenario (ilustrado na seguinte figura) ten menos parámetros.
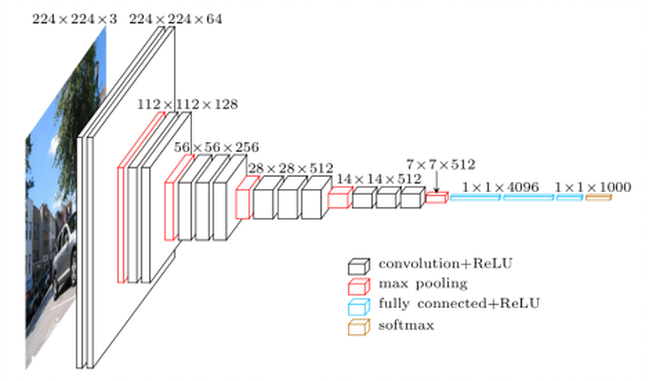
(imaxe tomada da rede, usada en varios blogs, como na Ilustración VGG16)
Para evitar a carga de capas que non imos usar, podemos invocar o método co parámetro include_top=False e para o tamaño específico que usamos (150 × 150150 \ veces 150150 × 150 píxeles)
if vgg16 != None: del vgg16 from keras.applications import VGG16conv_base = VGG16(weights='imagenet', include_top=False, input_shape=(150, 150, 3)) resumen(conv_base) ==================================================================================# Layer Name Layer Input Shape Layer Output Shape Parameters==================================================================================0 input_6 (None, 150, 150, 3) (None, 150, 150, 3) 01 block1_conv1 (None, 150, 150, 3) (None, 150, 150, 64) 17922 block1_conv2 (None, 150, 150, 64) (None, 150, 150, 64) 369283 block1_pool (None, 150, 150, 64) (None, 75, 75, 64) 04 block2_conv1 (None, 75, 75, 64) (None, 75, 75, 128) 738565 block2_conv2 (None, 75, 75, 128) (None, 75, 75, 128) 1475846 block2_pool (None, 75, 75, 128) (None, 37, 37, 128) 07 block3_conv1 (None, 37, 37, 128) (None, 37, 37, 256) 2951688 block3_conv2 (None, 37, 37, 256) (None, 37, 37, 256) 5900809 block3_conv3 (None, 37, 37, 256) (None, 37, 37, 256) 59008010 block3_pool (None, 37, 37, 256) (None, 18, 18, 256) 011 block4_conv1 (None, 18, 18, 256) (None, 18, 18, 512) 118016012 block4_conv2 (None, 18, 18, 512) (None, 18, 18, 512) 235980813 block4_conv3 (None, 18, 18, 512) (None, 18, 18, 512) 235980814 block4_pool (None, 18, 18, 512) (None, 9, 9, 512) 015 block5_conv1 (None, 9, 9, 512) (None, 9, 9, 512) 235980816 block5_conv2 (None, 9, 9, 512) (None, 9, 9, 512) 235980817 block5_conv3 (None, 9, 9, 512) (None, 9, 9, 512) 235980818 block5_pool (None, 9, 9, 512) (None, 4, 4, 512) 0__________________________________________________________________________________Total Parameters : 14714688Total Trainable Parameters : 14714688Total No-Trainable Parameters : 0son “só” menos de 15 millóns de parámetros, unha redución substancial con respecto ao VGG16 completo rede.
imos ver o resumo da rede KERAS
#conv_base.summary() A saída final do modelo base cargado (conv_base) ten o .
Rede pre-introducida como características extractoras offline
A primeira estratexia que imos usar para reutilizar o coñecemento almacenado (adquirido) por unha rede de clasificación e particularízala á nosa será considerar a extracción de trazos independentes da clasificación ión. É un enfoque de tipo sombrío (en oposición ao profundo). É dicir, pasaremos as imaxes á base da rede da rede (conv_base) e almacena as características da memoria ou disco (que é computacionalmente eficiente) e despois se alimenta con tales características dun clasificador. Isto está ilustrado na seguinte figura.

para xerar a codificación (encaixe ou incrustación) de imaxes e gatos Usará un xerador
É importante que usemos VGG16 preprocess os datos (imaxes) para normalizalos co mesmo procedemento que se usa para adestrar a rede orixinal. Neste caso, non é rescatalos ao intervalo, senón restar a media de cada canle de cor
import osimport numpy as npfrom tqdm import tqdmfrom keras.applications.imagenet_utils import preprocess_input#from tqdm import tqdm_notebook as tqdmfrom keras.preprocessing.image import ImageDataGeneratorbase_dir = '/home/mariano/Data/dogs_vs_cats_small'#base_dir = '/home/mariano/Documents/deep/kaggle/dogs_vs_cats_small'train_dir = os.path.join(base_dir, 'train')validation_dir = os.path.join(base_dir, 'validation')test_dir = os.path.join(base_dir, 'test')datagen = ImageDataGenerator(#rescale=1./255) preprocessing_function=preprocess_input)batch_size = 20def extract_features(directory, sample_count): ''' Codificador de imagenes mediante conv_base en rasgos para posteriormente usarlos como datos para una red clasificadora densa parámetros directory directorio con con los subdirectorios que definen clases sample_count número de muestras a generar resultados conjunto de características y etiquetas ''' # memoria para tensores con datos y etiquetas features = np.zeros(shape=(sample_count, 4, 4, 512)) labels = np.zeros(shape=(sample_count)) # instanciación del generador a partir del directorio donde estan las clases generator = datagen.flow_from_directory(directory, target_size = (150, 150), batch_size = batch_size, class_mode = 'binary') rango = list(range(int(sample_count/batch_size))) i = 0 with tqdm(total=len(rango)) as pbar: for inputs_batch, labels_batch in tqdm(generator): # características predichas (codificadas) por la subred base # para las imágenes generadas (aumentadas) en lote features_batch = conv_base.predict(inputs_batch) # datos y etiquetas features = features_batch labels = labels_batch i += 1 if i * batch_size >= sample_count: # La ejecucion del generador debe terminarse explícitamente después # usar todas la imágenes break pbar.update(1) return features, labelsConxunto de trazos de datos para a formación, Validación e proba
train_features, train_labels = extract_features(train_dir, 2000)validation_features, validation_labels = extract_features(validation_dir, 1000)test_features, test_labels = extract_features(test_dir, 1000) 0%| | 0/100 0%| | 0/100 3%|▎ | 3/100 ... 99%|█████████▉| 99/100 2%|▏ | 1/50 ... 98%|█████████▊| 49/50 2%|▏ | 1/50 ... 98%|█████████▊| 49/50 )import timetstart = time.time()history = model.fit(train_features, train_labels, epochs = 30, batch_size = 20, validation_data = (validation_features, validation_labels), verbose = 2)print('seconds=', time.time()-tstart)Train on 2000 samples, validate on 1000 samplesEpoch 1/30 - 1s - loss: 3.3298 - acc: 0.7205 - val_loss: 1.0112 - val_acc: 0.8950...Epoch 30/30 - 0s - loss: 0.0800 - acc: 0.9905 - val_loss: 0.3714 - val_acc: 0.9630seconds= 14.222734451293945 A formación é moi rápida Tendo en conta que a rede de clasificación consiste só en dúas capas Dense.
As curvas do valor de función de destino e precisión (accuracy) que se amosan a continuación.
import matplotlib.pyplot as pltacc = history.historyval_acc = history.historyloss = history.historyval_loss = history.historyepochs = range(len(acc))plt.plot(epochs, acc, 'bo', label='Entrenamiento acc')plt.plot(epochs, val_acc, 'b', label='Validación acc')plt.title('Accuracy - exactitud de entrenamiento y validación')plt.legend()plt.figure()plt.plot(epochs, loss, 'bo', label='Entrenamiento loss')plt.plot(epochs, val_loss, 'b', label='Validación loss')plt.title('Loss - función objetivo en entrenamiento y prueba')plt.legend()plt.show() 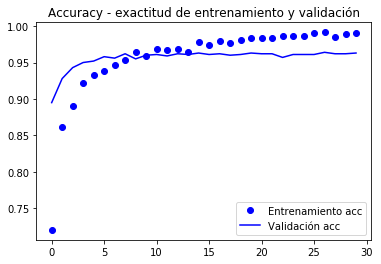
VALLATION alcanza o 90% de precisión, moito mellor que o modelo adestrado con aumento de datos e a paquea BD que alcanzou o 86%.
A curva de precisión ilustra que moi pronto comeza a ter un exceso de exceso (excesivamente). É porque non usamos o aumento de aumento.
Para implementar o aumento, debemos facer que a extracción de trazos se faga ao mesmo tempo que clasificamos, como modelo completo. Ben, en memoria ou disco non sería práctico almacenar o aumento dos datos para a súa posterior clasificación. Isto explícase a continuación.
Rede de transferencia de coñecemento de rede a novos problemas
O modelo CONV_BASE como capa de extracción de eliminación
Se asumimos que a etapa Convolutiva do VGG16 extrae as características xerais, será a parte que podemos reutilizar. As características extraídas deben ser aprobadas a un novo clasificador binario que debemos implementar e adestrar a ex profesión. Este proceso é MUSTRA na seguinte figura

Como a figura ilustra,
-
Reutilizamos só a etapa convolutiva da rede.
-
Definimos unha nova etapa de clasificación de acordo co noso problema.
-
Dende que temos, relativamente, poucos datos de adestramento, establecen a subred de extracción de funcións (conxelar os seus pesos) para evitar que se modifiquen en formación.
-
Adestramos Os pesos “viables”, os da etapa de clasificación facendo os nosos datos a través de toda a rede.
Usaremos xeradores de datos para facer un adestramento con xeradores (fit_generator), como no exemplo da sección anterior.
En KERAS todo son capas (capas), polo que usaremos o modelo conv_base como a primeira capa da rede, unha capa que calcula as características.
A continuación, engada ao novo modelo de capas de capas secuenciales Doras densas.
Esta técnica aínda que é sinxela de implementar a vergoña que cada unha imaxe aumentada pasa pola rede conv_base e despois a través do clasificador. Isto fai que os cálculos agora sexan máis caros e non é posible executalos en CPU, necesitamos unha GPU.
model.reset_states()from keras import modelsfrom keras import layersmodel = models.Sequential()model.add(conv_base) # modelo base agradado como una capa!model.add(layers.Flatten())model.add(layers.Dense(256, activation='relu'))#model.add(layers.Dropout(0.3)) # a vermodel.add(layers.Dense(1, activation='sigmoid'))Isto é o que parece o noso modelo agora:
#model.summary()resumen(model)==================================================================================# Layer Name Layer Input Shape Layer Output Shape Parameters==================================================================================0 vgg16 (None, 150, 150, 3) (None, 4, 4, 512) 147146881 flatten_1 (None, 4, 4, 512) (None, 8192) 02 dense_3 (None, 8192) (None, 256) 20974083 dense_4 (None, 256) (None, 1) 257__________________________________________________________________________________Total Parameters : 16812353Total Trainable Parameters : 16812353Total No-Trainable Parameters : 0A rede de convolución de base VGG16 15 Millóns de parámetros, que son moi grandes. O clasificador na parada engade outros 2 millóns de paradas.
Antes de adestrar “conxelaremos” a extracción de rede das características xa que temos algúns datos e queremos aproveitar o “coñecemento” almacenado na subreter base VGG16 que foi adestrado con moitas clases e debería ser Un extractor xeral de características.
Isto conseguimos marcar os pesos de “a capa” conv_base como non adestramento:
print('Número de pesos (matrices) entrenables antes de congelar conv_base : ', len(model.trainable_weights))Número de pesos (matrices) entrenables antes de congelar conv_base : 30conv_base.trainable = Falseprint('Número de pesos (matrices) entrenables después de congelar conv_base : ', len(model.trainable_weights))Número de pesos (matrices) entrenables después de congelar conv_base : 4resumen(model)==================================================================================# Layer Name Layer Input Shape Layer Output Shape Parameters==================================================================================0 vgg16 (None, 150, 150, 3) (None, 4, 4, 512) 147146881 flatten_1 (None, 4, 4, 512) (None, 8192) 02 dense_3 (None, 8192) (None, 256) 20974083 dense_4 (None, 256) (None, 1) 257__________________________________________________________________________________Total Parameters : 16812353Total Trainable Parameters : 2097665Total No-Trainable Parameters : 14714688O número de matrices supera as capas porque cada capa pode ter unha matriz de peso www e un vector de bias bbb.
Para facer conxelación de datos necesitamos compilar o modelo e, a continuación, definir os parámetros do xerador.
from keras.preprocessing.image import ImageDataGeneratorfrom keras import modelsfrom keras import layersfrom keras import optimizerstrain_datagen = ImageDataGenerator(#rescale = 1./255, preprocessing_function=preprocess_input, rotation_range = 40, width_shift_range = 0.2, height_shift_range= 0.2, shear_range = 0.2, zoom_range = 0.2, horizontal_flip = True, fill_mode = 'constant', #'nearest') cval = 0)# La validación no se aumenta!test_datagen = ImageDataGenerator(#rescale=1./255) preprocessing_function=preprocess_input)train_generator = train_datagen.flow_from_directory( train_dir, # directorio con datos de entrenamiento target_size= (150, 150), # tamaño de la imágenes batch_size = 20, shuffle = True, class_mode = 'binary') # para clasificación binariavalidation_generator = test_datagen.flow_from_directory( validation_dir, target_size=(150, 150), batch_size=20, class_mode='binary')model.compile(loss='binary_crossentropy', optimizer=keras.optimizers.Nadam(lr=2e-5), #optimizers.RMSprop(lr=2e-5), metrics=)#model.reset_states()import timetstart = time.time()history = model.fit_generator(train_generator, steps_per_epoch = 100, epochs = 30, validation_data = validation_generator, validation_steps= 50, verbose = 2)print('seconds=', time.time()-tstart)Found 2000 images belonging to 2 classes.Found 1000 images belonging to 2 classes.Epoch 1/30 - 10s - loss: 1.9860 - acc: 0.7660 - val_loss: 0.7680 - val_acc: 0.9040Epoch 2/30 - 9s - loss: 0.9115 - acc: 0.8815 - val_loss: 0.5760 - val_acc: 0.9210...Epoch 30/30 - 9s - loss: 0.1956 - acc: 0.9640 - val_loss: 0.3213 - val_acc: 0.9660seconds= 281.5276675224304model.save('cats_and_dogs_small_3.h5')gráficamente gráfico o comportamento das métricas gravadas durante a nación
import matplotlib.pyplot as pltacc = history.historyval_acc = history.historyloss = history.historyval_loss = history.historyepochs = range(len(acc))plt.plot(epochs, acc, 'bo', label='Entrenamiento acc')plt.plot(epochs, val_acc, 'b', label='Validación acc')plt.title('Accuracy - exactitud de entrenamiento y validación')plt.legend()plt.figure()plt.plot(epochs, loss, 'bo', label='Entrenamiento loss')plt.plot(epochs, val_loss, 'b', label='Validación loss')plt.title('Loss - función objetivo en entrenamiento y prueba')plt.legend()plt.show() 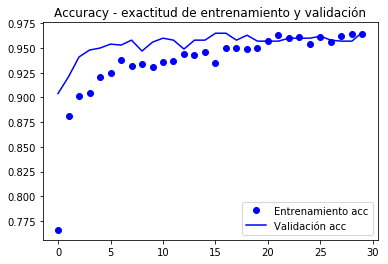
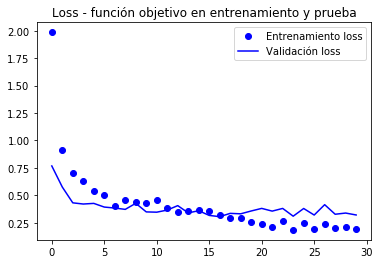
Segundo o autor do libro (Chollet), alcánzase unha precisión de preto do 96,5%.
Axuste fino
Outra estratexia amplamente utilizada na reutilización de refinamento é o axuste fino (axustado), que é compatible que, unha vez que unha capa de clasificación con pretrenetrán, foi adestrada, descongelou a As últimas capas de base convolutiva para permitir que os seus pesos se adapten mellor á capa de clasificación. Lograr unha mellor integración entre a base (adestrada por un problema diferente) e a clasificación.
Os pasos de formación fina son:
- Engadir a unha base de place Convolutivo xeral Clasificación final.
- Conxelar a base convolutiva.
- Formar a fase de clasificación.
- Defrost as últimas capas da base convolutiva.
- Etapa de clasificación de adestrar e as últimas capas do conxunto conxunto.
Partedo do modelo anterior anterior (pasos 1,2 e 3) Vemos que as capas para descongelar son as correspondentes a Block5.
Como recordatorio o resumo da convolución é
resumen(conv_base)==================================================================================# Layer Name Layer Input Shape Layer Output Shape Parameters==================================================================================0 input_6 (None, 150, 150, 3) (None, 150, 150, 3) 01 block1_conv1 (None, 150, 150, 3) (None, 150, 150, 64) 17922 block1_conv2 (None, 150, 150, 64) (None, 150, 150, 64) 369283 block1_pool (None, 150, 150, 64) (None, 75, 75, 64) 04 block2_conv1 (None, 75, 75, 64) (None, 75, 75, 128) 738565 block2_conv2 (None, 75, 75, 128) (None, 75, 75, 128) 1475846 block2_pool (None, 75, 75, 128) (None, 37, 37, 128) 07 block3_conv1 (None, 37, 37, 128) (None, 37, 37, 256) 2951688 block3_conv2 (None, 37, 37, 256) (None, 37, 37, 256) 5900809 block3_conv3 (None, 37, 37, 256) (None, 37, 37, 256) 59008010 block3_pool (None, 37, 37, 256) (None, 18, 18, 256) 011 block4_conv1 (None, 18, 18, 256) (None, 18, 18, 512) 118016012 block4_conv2 (None, 18, 18, 512) (None, 18, 18, 512) 235980813 block4_conv3 (None, 18, 18, 512) (None, 18, 18, 512) 235980814 block4_pool (None, 18, 18, 512) (None, 9, 9, 512) 015 block5_conv1 (None, 9, 9, 512) (None, 9, 9, 512) 235980816 block5_conv2 (None, 9, 9, 512) (None, 9, 9, 512) 235980817 block5_conv3 (None, 9, 9, 512) (None, 9, 9, 512) 235980818 block5_pool (None, 9, 9, 512) (None, 4, 4, 512) 0__________________________________________________________________________________Total Parameters : 14714688Total Trainable Parameters : 14714688Total No-Trainable Parameters : 0 faremos O axuste fino nas últimas tres capas convolutivas: block5_conv1, block5_conv2 e block5_conv3.
É importante notar que as primeiras capas Código de información máis xeral para que non sexa conveniente Renéctanos se o propósito é reutilizar o coñecemento. Terminaríamos sobre o sobreestar o modelo a pequenas nustras BD.
# Orden de las capas for layer in conv_base.layers: print(layer.name)input_6block1_conv1block1_conv2block1_poolblock2_conv1block2_conv2block2_poolblock3_conv1block3_conv2block3_conv3block3_poolblock4_conv1block4_conv2block4_conv3block4_poolblock5_conv1block5_conv2block5_conv3block5_poolconv_base.trainable = Trueset_trainable = Falsefor layer in conv_base.layers: if layer.name in : layer.trainable = True else: layer.trainable = False resumen(conv_base) ==================================================================================# Layer Name Layer Input Shape Layer Output Shape Parameters==================================================================================0 input_6 (None, 150, 150, 3) (None, 150, 150, 3) 01 block1_conv1 (None, 150, 150, 3) (None, 150, 150, 64) 17922 block1_conv2 (None, 150, 150, 64) (None, 150, 150, 64) 369283 block1_pool (None, 150, 150, 64) (None, 75, 75, 64) 04 block2_conv1 (None, 75, 75, 64) (None, 75, 75, 128) 738565 block2_conv2 (None, 75, 75, 128) (None, 75, 75, 128) 1475846 block2_pool (None, 75, 75, 128) (None, 37, 37, 128) 07 block3_conv1 (None, 37, 37, 128) (None, 37, 37, 256) 2951688 block3_conv2 (None, 37, 37, 256) (None, 37, 37, 256) 5900809 block3_conv3 (None, 37, 37, 256) (None, 37, 37, 256) 59008010 block3_pool (None, 37, 37, 256) (None, 18, 18, 256) 011 block4_conv1 (None, 18, 18, 256) (None, 18, 18, 512) 118016012 block4_conv2 (None, 18, 18, 512) (None, 18, 18, 512) 235980813 block4_conv3 (None, 18, 18, 512) (None, 18, 18, 512) 235980814 block4_pool (None, 18, 18, 512) (None, 9, 9, 512) 015 block5_conv1 (None, 9, 9, 512) (None, 9, 9, 512) 235980816 block5_conv2 (None, 9, 9, 512) (None, 9, 9, 512) 235980817 block5_conv3 (None, 9, 9, 512) (None, 9, 9, 512) 235980818 block5_pool (None, 9, 9, 512) (None, 4, 4, 512) 0__________________________________________________________________________________Total Parameters : 14714688Total Trainable Parameters : 7079424Total No-Trainable Parameters : 7635264 Nota agora que o conv_base ten adestramento e participación non adestable.
para adestramento fino procedemos a compilar o modelo cun pequeno tamaño de paso para evitar grandes cambios nos pesos, xa que supoñemos que está preto do óptimo e que o axuste non debe ser moi grande.
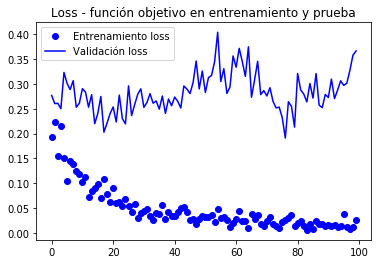
model.compile(loss='binary_crossentropy', optimizer=optimizers.RMSprop(lr=1e-5), metrics=)history = model.fit_generator( train_generator, steps_per_epoch=100, epochs=100, validation_data=validation_generator, validation_steps=50)Epoch 1/100100/100 - 10s 104ms/step - loss: 0.1938 - acc: 0.9645 - val_loss: 0.2769 - val_acc: 0.9580Epoch 2/100100/100 - 9s 94ms/step - loss: 0.2239 - acc: 0.9635 - val_loss: 0.2606 - val_acc: 0.9650... Epoch 100/100100/100 - 10s 97ms/step - loss: 0.0269 - acc: 0.9960 - val_loss: 0.3666 - val_acc: 0.9620model.save('cats_and_dogs_small_4.h5')Gráficos de métricas rexistradas durante a formación
import matplotlib.pyplot as pltacc = history.historyval_acc = history.historyloss = history.historyval_loss = history.historyepochs = range(len(acc))plt.plot(epochs, acc, 'bo', label='Entrenamiento acc')plt.plot(epochs, val_acc, 'b', label='Validación acc')plt.title('Accuracy - exactitud de entrenamiento y validación')plt.legend()plt.figure()plt.plot(epochs, loss, 'bo', label='Entrenamiento loss')plt.plot(epochs, val_loss, 'b', label='Validación loss')plt.title('Loss - función objetivo en entrenamiento y prueba')plt.legend()plt.show() 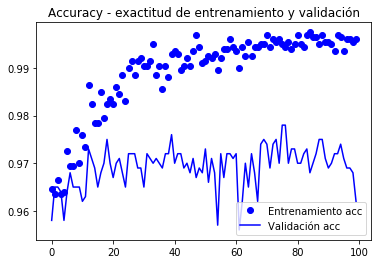
Dado que as curvas son moi ruidosas, É posible filtralos para apreciar mellor a tendencia mediante un filtro de paso baixo, pódese probar
s ~ i = σk = 0nwsi-k \ tilde s_i = \ sum_ {k = 0} ^ n w_k s_ {ik} s ~ i = k = 0σnwksi-k
Onde www é un PESOS CO n σkwk = 1 \ sum_k w_k = 1σkwk = 1; Pero necesitaremos un filtro bastante amplo (grande NNN) para eliminar correctamente o ruído, no seu lugar, probamos a versión recursiva (como no libro sobre o que se basean estas notas)
i
s ~ i = αs ~ i -1+ (1-α) se \ tilde s_i = \ alpha \ tilde s_ {i-1} + (1- α) s_is ~ i = αs ~ i-1 + (1-α) se
que usas os datos actualizados recentemente cun procedemento similar. Estes filtros recursivos pódense expresar como non recursivos (substituíndo os datos actualizados pola súa fórmula). A vantaxe da forma recursiva é o compacto da expresión de actualización
def smooth_curve(points, factor=0.8): smoothed_points = for point in points: if smoothed_points: previous = smoothed_points smoothed_points.append(previous * factor + point * (1 - factor)) else: smoothed_points.append(point) return smoothed_pointsimport matplotlib.pyplot as pltacc = history.historyval_acc = history.historyloss = history.historyval_loss = history.historyepochs = range(len(acc))alpha = 0.9plt.plot(epochs, smooth_curve(acc, alpha), 'bo', label='Entrenamiento acc')plt.plot(epochs, smooth_curve(val_acc, alpha), 'b', label='Validación acc')plt.title('Accuracy - exactitud de entrenamiento y validación')plt.legend()plt.figure()plt.plot(epochs, smooth_curve(loss, alpha), 'bo', label='Entrenamiento loss')plt.plot(epochs, smooth_curve(val_loss,alpha), 'b', label='Validación loss')plt.title('Loss - función objetivo en entrenamiento y prueba')plt.legend()plt.show() 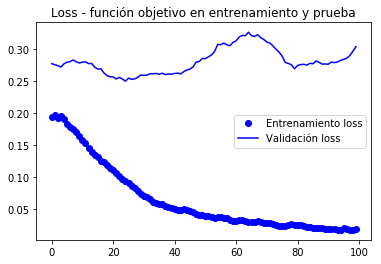
Nestas curvas pode apreciar mellor a tendencia, podemos notar que era unha mellora dun 1%.
En (Chollet, 2018) A observación faise que a precisión mellora incluso cando a perda non. Isto ocorre porque a perda é avaliada por un proceso de suma de erro no vector de saída, algo así como:
σi∈epoch∥yi-y ^ i∥m \ sum_ {i \ in époch} \ | Y_i – \ hat y_i \ | _Mi∈epoch∥∥∥yi-y ^ i∥m
Onde supoñemos que a yyy está nunha codificación única e m indica algunha métrica.Por outra banda, a precisión calcúlase mediante un rescate de suma de erros:
σi∈epoch1-δ (argmaxiyi-argmaxiy ^ i) \ sum_ {i en época } 1- δ (τ \ rm \ max_i {\ hat y_i}) ∈epochς1-δ (argimaxyi-argimaxy ^ i)
agora avaliar, finalmente e perecer, o conxunto de probas:
Found 1000 images belonging to 2 classes.test acc: 0.9669999933242798* moi preto do 97%
No concurso de Kaggle orixinal, estaría entre os mellores resultados (arriba), e que só usamos 2000 datos de formación vs. 20.000 na competición de Kaggle.
Resumo
-
As redes convolucionais son o mellor modelo de redes neuronais para xestionar o procesamento de imaxes e problemas de visión de computadores.
-
O aumento de datos permítelle evitar ecumosar en redes base de datos e aumentar con datos sintéticos do tamaño da mostra de formación
-
é posible Para usar modelos de pre-intención na fase de extracción de funcións para tratar con pequenas bases de datos.
-
O axuste fino permite mellorar a interconexión da etapa predefinida coa etapa constante, mellorando o xeneral rendemento a un baixo custo computacional.