Transferència de coneixement (Knowledge Transfering)
Basat en l’exemple 5.3 de F Chollet, Deep Learning with Python, Ed Manning, 2018
Mariano Rivera a versió 1.0 a març 2019
import osos.environ="PCI_BUS_ID";os.environ="1"; import keraskeras.__version__Using TensorFlow backend.'2.2.4'VGG16: Una Xarxa convolucional Preentrenada
Una estratègia per lluitar en xarxes neuronals profundes és usar xarxes prèviament preentrenadas amb bases de dades grans i adaptar-les a el problema del nostre interès.
per a aquest propòsit és necessari que la xarxa preentrenada hagi estat entrenada per resoldre un problema de caràcter més general, de què el nostre problema es pugui va considerar un cas particular. Per exemple, per al cas de classificar gossos i gats podem utilitzar una xarxa entrenada per classificar mes classes com l’anomenada VGG16 (Simonyan and Zisserman, 2015). Les raons que per la qual fem servir VGG16 són les següents
-
Té una arquitectura fàcil de comprendre i, si escau, d’implementar.
-
Aconsegueix un excel·lent resultat en la competència ImageNet (ILSVRC-2014), entre el 96% i 97%.
-
Contenen relativament poques capes convolucionals: 13 capes convolucionals i 3 denses, per aquest motiu en els seus nom inclogui el 16.
-
La xarxa (model i pesos entrenats) aquesta diponible en Kera
(Simonyan and Zisserman, 2015) K. Simonyan and A. Zisserman, Very Deep Convolutional Networks for Large-Scale Image Recognition, 3rd ICLR 2015.
Les xarxes diponibles en keras que van ser entrenades en la BD ImageNet són
- Xception
- InceptionV3
- ResNet50
- VGG16
- VGG19
- MobileNet
la xarxa VGG19 és una variant amb mes capes de càlcul que la VGG16, per tant mes pesada d’emmagatzemar en memòria i en requeriments de còmput.
Co mo veiem, atès que VGG16 va ser entrenada per resoldre el problema de classificació de 1000 classes a ImageNet, deu en els seus pesos codificar informació per extreure trets de molt diferents classes de representradas a les més de 1,4 milions de fotografies de ImageNet. Entre aquestes classes hi ha molt diferents varietats d’animals, en molt diferents entorns. Per això, VGG16 és una molt bona candidata per ser particularitzada a el problema de classificació binari de gossos i gats.
Notem que hi ha arquitectures més modernes, amb millors acompliments, però VGG16 servirà molt bé per al nostre propòsit. Com hem vist en els exemples anteriors, les xarxes convolucionals per classificació segueixen una estructura de dos blocs:
-
Etapa de capes convolucionals per a extracció de trets
-
Etapa de decisió basada en capes denses.
VGG16 segueix fidelment aquesta arquitectura. Veure la siginete figura
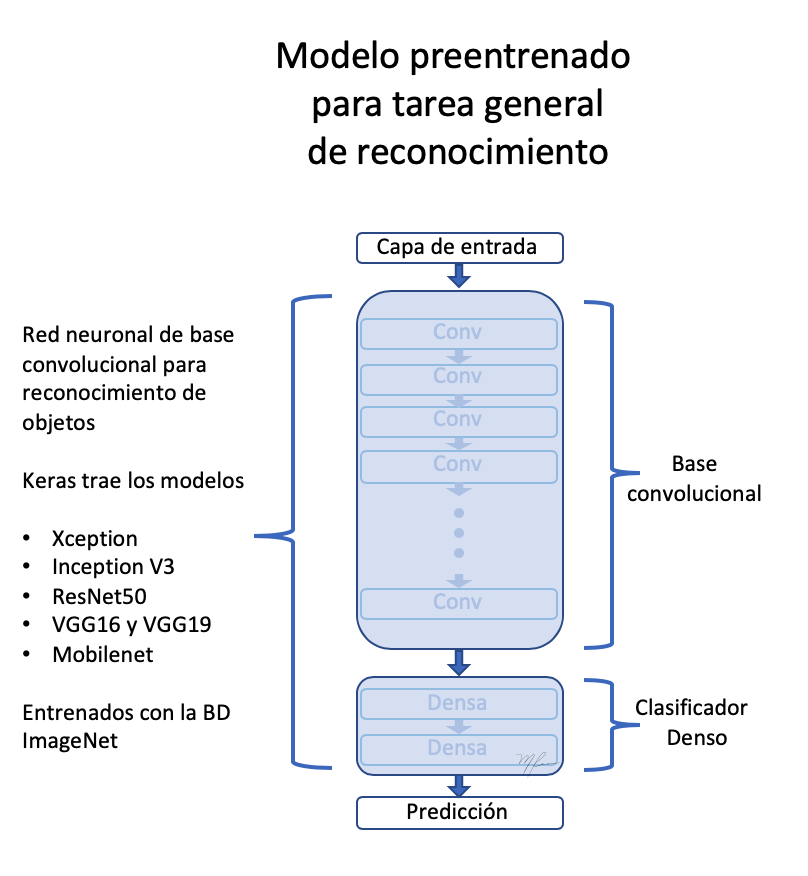
L’usar la VGG16 entrenada prèviament amb la BD ImageNet ens permet assumir que la seva etapa de extracció de trets codifica, efectivament, les relacions epaciales que fan als objectes distingibles i per la bastedad de ImageNet, ens fa assumir que aquestes relacions espacials són els suficientment genèriques per poder codificar trets distintius de gossos i gats.
Anirem pas a pas, primer carreguem la xarxa VGG16 dins el paquet keras.applications.
Accés als Components d’una xarxa convolucional Preentrenada
Vegem com carregar un model preentrenado i com podem tenir accés als seus components. A manera d’il·lustració definim la nostra versió de la funció summary dels models de keras. Amb això vam mostrar com accedir als noms de les capes, les seves nombre de paràmetres, etc.
def resumen(model=None): ''' ''' header = '{:4} {:16} {:24} {:24} {:10}'.format('#', 'Layer Name','Layer Input Shape','Layer Output Shape','Parameters' ) print('='*(len(header))) print(header) print('='*(len(header))) count=0 count_trainable=0 for i, layer in enumerate(model.layers): count_trainable += layer.count_params() if layer.trainable else 0 input_shape = '{}'.format(layer.input_shape) output_shape = '{}'.format(layer.output_shape) str = '{:<4d} {:16} {:24} {:24} {:10}'.format(i,layer.name, input_shape, output_shape, layer.count_params()) print(str) count += layer.count_params() print('_'*(len(header))) print('Total Parameters : ', count) print('Total Trainable Parameters : ', count_trainable) print('Total No-Trainable Parameters : ', count-count_trainable) vgg16=NoneDesprés carreguem el model VGG16 amb els següents paràmetres:
-
weights indica que pesos seran els usats per inicialitzar el model
-
include_top indica si es carrega la xarxa completa (extracció de característiques i etapa de decisió) o només l’etapa de extracció de resgos
-
input_shape la forma de les imatges a processar (opcional, atès que la xarxa pueded processar qualsevol dimensió d’imatges)
from keras.applications import VGG16vgg16 = VGG16(weights='imagenet', include_top=True, input_shape=(224, 224, 3))resumen(vgg16)==================================================================================# Layer Name Layer Input Shape Layer Output Shape Parameters==================================================================================0 input_5 (None, 224, 224, 3) (None, 224, 224, 3) 01 block1_conv1 (None, 224, 224, 3) (None, 224, 224, 64) 17922 block1_conv2 (None, 224, 224, 64) (None, 224, 224, 64) 369283 block1_pool (None, 224, 224, 64) (None, 112, 112, 64) 04 block2_conv1 (None, 112, 112, 64) (None, 112, 112, 128) 738565 block2_conv2 (None, 112, 112, 128) (None, 112, 112, 128) 1475846 block2_pool (None, 112, 112, 128) (None, 56, 56, 128) 07 block3_conv1 (None, 56, 56, 128) (None, 56, 56, 256) 2951688 block3_conv2 (None, 56, 56, 256) (None, 56, 56, 256) 5900809 block3_conv3 (None, 56, 56, 256) (None, 56, 56, 256) 59008010 block3_pool (None, 56, 56, 256) (None, 28, 28, 256) 011 block4_conv1 (None, 28, 28, 256) (None, 28, 28, 512) 118016012 block4_conv2 (None, 28, 28, 512) (None, 28, 28, 512) 235980813 block4_conv3 (None, 28, 28, 512) (None, 28, 28, 512) 235980814 block4_pool (None, 28, 28, 512) (None, 14, 14, 512) 015 block5_conv1 (None, 14, 14, 512) (None, 14, 14, 512) 235980816 block5_conv2 (None, 14, 14, 512) (None, 14, 14, 512) 235980817 block5_conv3 (None, 14, 14, 512) (None, 14, 14, 512) 235980818 block5_pool (None, 14, 14, 512) (None, 7, 7, 512) 019 flatten (None, 7, 7, 512) (None, 25088) 020 fc1 (None, 25088) (None, 4096) 10276454421 fc2 (None, 4096) (None, 4096) 1678131222 predictions (None, 4096) (None, 1000) 4097000__________________________________________________________________________________Total Parameters : 138357544Total Trainable Parameters : 138357544Total No-Trainable Parameters : 0
Són prop de 139 milions de paràmetres. Realment va consumir temps decarregar el model complet (es realitza només per a primera vegada que s’invoca la funció VGG16. Notem que, afortunadament, molts dels paràmetres (com el 90%) corresponen a l’etapa de decisió. L’etapa d’extracció de trets ( il·lustrada en la figura) té menys paràmetres.
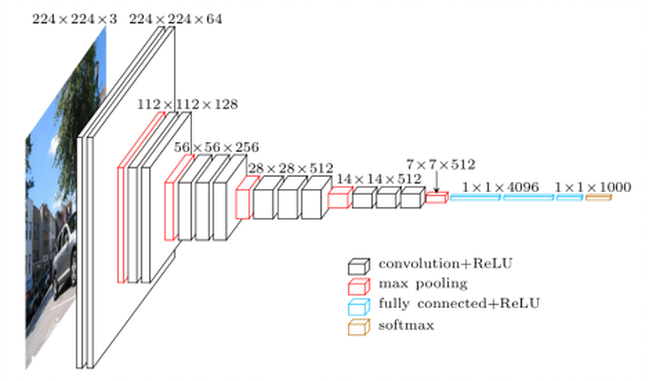
(Imatge presa de la xarxa, usada en diversos blocs, com en la il·lustració de vgg16)
per evitar carregar capes que no farem servir podem invocar el mètode amb el paràmetre include_top=False i per al tamañno específic que hem fet servir (150 × 150.150 \ times 150.150 × 150 píxels)
if vgg16 != None: del vgg16 from keras.applications import VGG16conv_base = VGG16(weights='imagenet', include_top=False, input_shape=(150, 150, 3)) resumen(conv_base) ==================================================================================# Layer Name Layer Input Shape Layer Output Shape Parameters==================================================================================0 input_6 (None, 150, 150, 3) (None, 150, 150, 3) 01 block1_conv1 (None, 150, 150, 3) (None, 150, 150, 64) 17922 block1_conv2 (None, 150, 150, 64) (None, 150, 150, 64) 369283 block1_pool (None, 150, 150, 64) (None, 75, 75, 64) 04 block2_conv1 (None, 75, 75, 64) (None, 75, 75, 128) 738565 block2_conv2 (None, 75, 75, 128) (None, 75, 75, 128) 1475846 block2_pool (None, 75, 75, 128) (None, 37, 37, 128) 07 block3_conv1 (None, 37, 37, 128) (None, 37, 37, 256) 2951688 block3_conv2 (None, 37, 37, 256) (None, 37, 37, 256) 5900809 block3_conv3 (None, 37, 37, 256) (None, 37, 37, 256) 59008010 block3_pool (None, 37, 37, 256) (None, 18, 18, 256) 011 block4_conv1 (None, 18, 18, 256) (None, 18, 18, 512) 118016012 block4_conv2 (None, 18, 18, 512) (None, 18, 18, 512) 235980813 block4_conv3 (None, 18, 18, 512) (None, 18, 18, 512) 235980814 block4_pool (None, 18, 18, 512) (None, 9, 9, 512) 015 block5_conv1 (None, 9, 9, 512) (None, 9, 9, 512) 235980816 block5_conv2 (None, 9, 9, 512) (None, 9, 9, 512) 235980817 block5_conv3 (None, 9, 9, 512) (None, 9, 9, 512) 235980818 block5_pool (None, 9, 9, 512) (None, 4, 4, 512) 0__________________________________________________________________________________Total Parameters : 14714688Total Trainable Parameters : 14714688Total No-Trainable Parameters : 0Són “només” poc menys de 15 milions de paràmetres, una reducció substancial respecte a la xarxa VGG16 completa .
Vegem el resum de la xarxa de Keras
#conv_base.summary() la sortida final d’el model base carregat (conv_base) tenen la forma (4, 4, 512).
Xarxa Preentrenada com Extractor Trets Fora de Línia
la primera estratègia que farem servir per reutilitzar el coneixement emmagatzemat (adquirit) per una xarxa classificadora i particularitzar al nostre serà al considerar l’extracció de trets independent de la clasificac ió. És un enfocament de l’tipus succint (en contraposició amb el profund). És a dir, passarem les imatges a la xarxa convolucional base (conv_base) i emmagatzemarem en memòria o disc les característiques (el que és computacionalment eficient) per després alimentar amb aquests trets un classificador. Això es mostra a la següent figura.
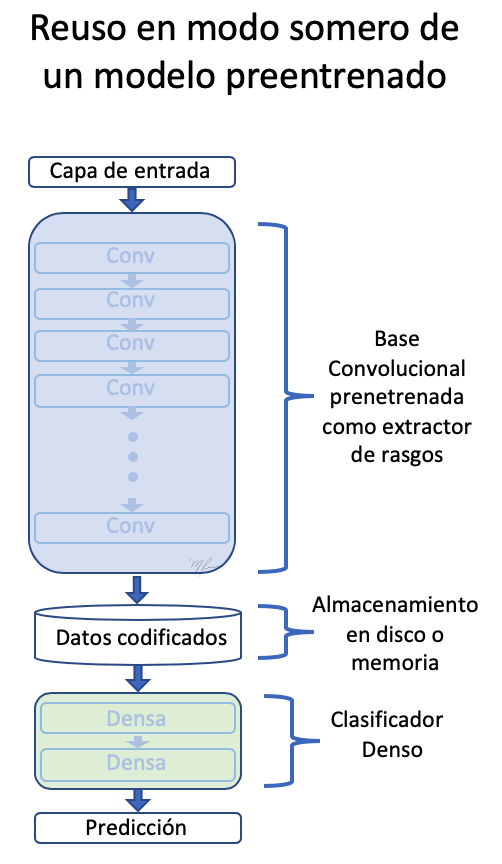
Per generar la codificació (encaix o embedding) de les imatges de gossos i gats farem servir un generador
És important si fem servir VGG16 preprocessar les dades (imatges) per normalitzar amb el mateix procediment que ús per entrenar la xarxa original. En aquest cas, no és reescalarlas a l’interval, sinó restar la mitjana de cada canal de color
import osimport numpy as npfrom tqdm import tqdmfrom keras.applications.imagenet_utils import preprocess_input#from tqdm import tqdm_notebook as tqdmfrom keras.preprocessing.image import ImageDataGeneratorbase_dir = '/home/mariano/Data/dogs_vs_cats_small'#base_dir = '/home/mariano/Documents/deep/kaggle/dogs_vs_cats_small'train_dir = os.path.join(base_dir, 'train')validation_dir = os.path.join(base_dir, 'validation')test_dir = os.path.join(base_dir, 'test')datagen = ImageDataGenerator(#rescale=1./255) preprocessing_function=preprocess_input)batch_size = 20def extract_features(directory, sample_count): ''' Codificador de imagenes mediante conv_base en rasgos para posteriormente usarlos como datos para una red clasificadora densa parámetros directory directorio con con los subdirectorios que definen clases sample_count número de muestras a generar resultados conjunto de características y etiquetas ''' # memoria para tensores con datos y etiquetas features = np.zeros(shape=(sample_count, 4, 4, 512)) labels = np.zeros(shape=(sample_count)) # instanciación del generador a partir del directorio donde estan las clases generator = datagen.flow_from_directory(directory, target_size = (150, 150), batch_size = batch_size, class_mode = 'binary') rango = list(range(int(sample_count/batch_size))) i = 0 with tqdm(total=len(rango)) as pbar: for inputs_batch, labels_batch in tqdm(generator): # características predichas (codificadas) por la subred base # para las imágenes generadas (aumentadas) en lote features_batch = conv_base.predict(inputs_batch) # datos y etiquetas features = features_batch labels = labels_batch i += 1 if i * batch_size >= sample_count: # La ejecucion del generador debe terminarse explícitamente después # usar todas la imágenes break pbar.update(1) return features, labelsConjunt de dades-trets per a entrenament, validació i prova
train_features, train_labels = extract_features(train_dir, 2000)validation_features, validation_labels = extract_features(validation_dir, 1000)test_features, test_labels = extract_features(test_dir, 1000) 0%| | 0/100 0%| | 0/100 3%|▎ | 3/100 ... 99%|█████████▉| 99/100 2%|▏ | 1/50 ... 98%|█████████▊| 49/50 2%|▏ | 1/50 ... 98%|█████████▊| 49/50 )import timetstart = time.time()history = model.fit(train_features, train_labels, epochs = 30, batch_size = 20, validation_data = (validation_features, validation_labels), verbose = 2)print('seconds=', time.time()-tstart)Train on 2000 samples, validate on 1000 samplesEpoch 1/30 - 1s - loss: 3.3298 - acc: 0.7205 - val_loss: 1.0112 - val_acc: 0.8950...Epoch 30/30 - 0s - loss: 0.0800 - acc: 0.9905 - val_loss: 0.3714 - val_acc: 0.9630seconds= 14.222734451293945 l’entrenament és molt ràpid atès que la xarxa classificadora consta únicament de dues capes Dense.
les corbes de la valor funció objectiu i l’exactitud (accuracy) es mostren a continuació.
import matplotlib.pyplot as pltacc = history.historyval_acc = history.historyloss = history.historyval_loss = history.historyepochs = range(len(acc))plt.plot(epochs, acc, 'bo', label='Entrenamiento acc')plt.plot(epochs, val_acc, 'b', label='Validación acc')plt.title('Accuracy - exactitud de entrenamiento y validación')plt.legend()plt.figure()plt.plot(epochs, loss, 'bo', label='Entrenamiento loss')plt.plot(epochs, val_loss, 'b', label='Validación loss')plt.title('Loss - función objetivo en entrenamiento y prueba')plt.legend()plt.show() 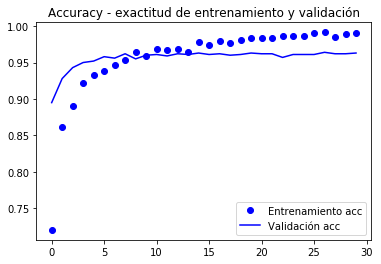
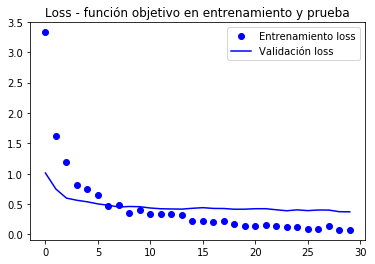
la valicación arriba als 90% d’exactitud, molt millor que el model entrenat amb augmentació de dades i la BD paqueña que va aconseguir un 86%.
la corba de l’exactitud il·lustra que molt aviat es comença a tenir un sobreajust (overfitting). Es deu al fet que no fem servir augmentació.
Per implementar augmentació hem de fer que l’extracció de trets es faci alhora que classifiquem, com un model complet. Doncs en memòria o disc seria poc pràctic emmagatzemar les dades augmentats per al seu posterior classificació. Això ho expliquem a continuació.
Transferència de Coneixement de Xarxes Preentrenadas a Nous Problemes
El model conv_base com a capa d’extracció de resgos
Si assumim que etapa convolucional de la VGG16 extreu caractéristicas generals, serà aquesta la part que puguem reutilitzar. Les característiques extretes han de ser passades a un nou classificador binari que hem d’implementar i entrenar ex-professo. Aquest procés es mustra en la següent figura
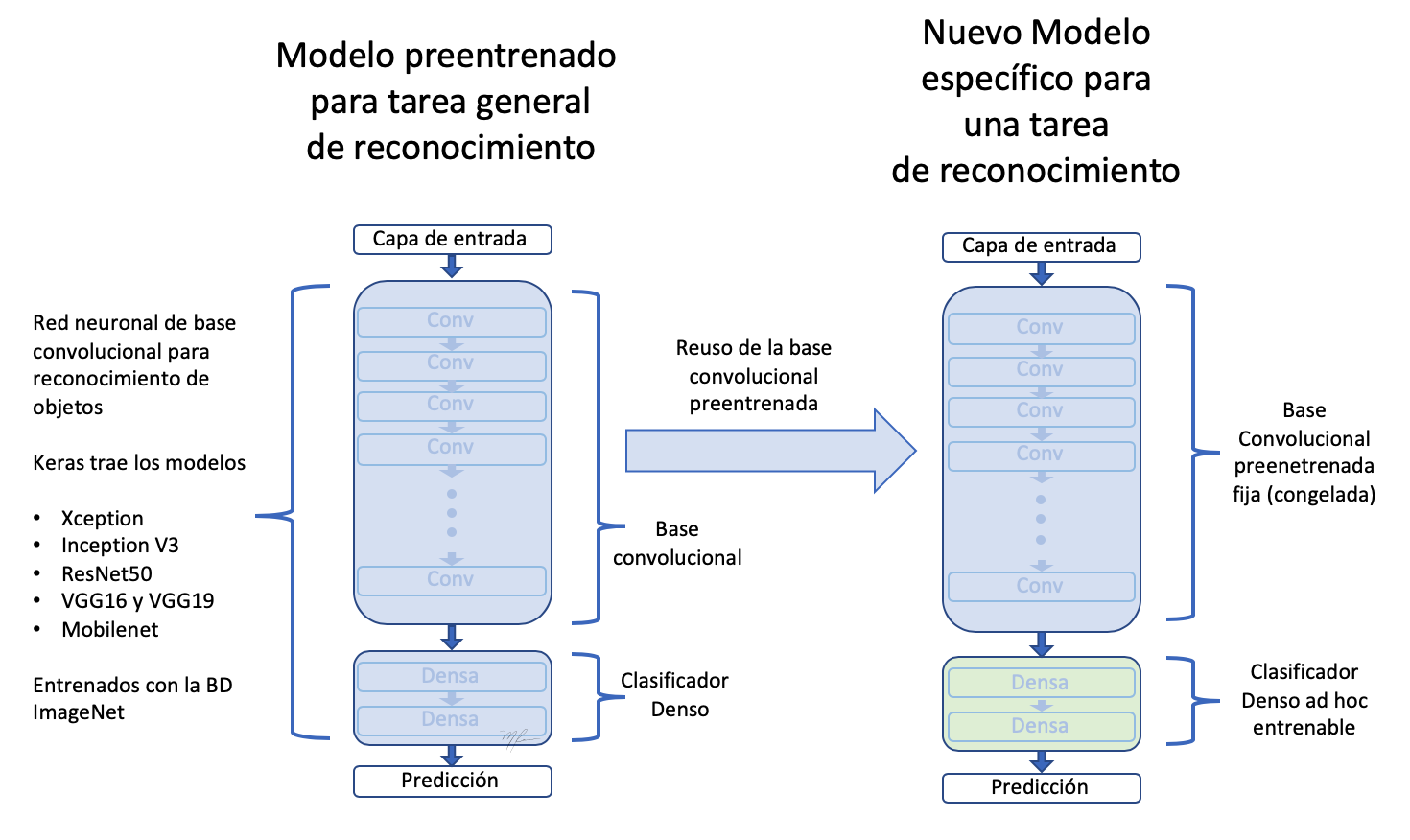
Com la figura il·lustra,
-
Reusamos només l’etapa convolucional de la xarxa.
-
Definim una nova etapa de classificació d’acord al nostre problema.
-
Com que tenim, relativament, poques dades d’entrenament, fixem la subxarxa d’extracció de trets (congelem els seus pesos) per evitar que siguin modificats en l’entrenament.
-
Entrenem els pesos “entrenables”, els de l’etapa de classificació fent-passar el nostre dades per tota la xarxa.
Farem servir els generadors de dades per fer un entrenament amb generadors (fit_generator), com en l’exemple de la secció anterior.
en Keras tot són capes (layers), de manera que farem servir el model conv_base com la primera capa de la xarxa, una capa que calcula trets.
Després afegim a el nou model seqüencial capes classifica dores denses.
Aquesta tècnica encara que simple d’implementar farà que cada imatge augmentada sigui passada per la xarxa conv_base i després per la classificadora. Això fa que els càlculs siguin ara més costosos i no és possible realitzar-los en CPU, requerim d’una GPU.
model.reset_states()from keras import modelsfrom keras import layersmodel = models.Sequential()model.add(conv_base) # modelo base agradado como una capa!model.add(layers.Flatten())model.add(layers.Dense(256, activation='relu'))#model.add(layers.Dropout(0.3)) # a vermodel.add(layers.Dense(1, activation='sigmoid'))This is what our model looks like now:
#model.summary()resumen(model)==================================================================================# Layer Name Layer Input Shape Layer Output Shape Parameters==================================================================================0 vgg16 (None, 150, 150, 3) (None, 4, 4, 512) 147146881 flatten_1 (None, 4, 4, 512) (None, 8192) 02 dense_3 (None, 8192) (None, 256) 20974083 dense_4 (None, 256) (None, 1) 257__________________________________________________________________________________Total Parameters : 16812353Total Trainable Parameters : 16812353Total No-Trainable Parameters : 0La xarxa convolucional base VGG16 htienen gairebé 15 milions de paràmetres, el que és molt gran. El classificador al límit afegeix altres 2 millions de parámetetros.
Abans d’entrenar “congelarem” la xarxa extracció de trets ja que comptem amb poques dades i volem aprofitar “el coneixement” emmagatzemat a la subxarxa base de VGG16 que va ser entrenada amb moltes classes i ha de ser un extractor molt general de característiques.
Això ho aconseguim marcant els pesos de “la capa” conv_base com no-entrenable:
print('Número de pesos (matrices) entrenables antes de congelar conv_base : ', len(model.trainable_weights))Número de pesos (matrices) entrenables antes de congelar conv_base : 30conv_base.trainable = Falseprint('Número de pesos (matrices) entrenables después de congelar conv_base : ', len(model.trainable_weights))Número de pesos (matrices) entrenables después de congelar conv_base : 4resumen(model)==================================================================================# Layer Name Layer Input Shape Layer Output Shape Parameters==================================================================================0 vgg16 (None, 150, 150, 3) (None, 4, 4, 512) 147146881 flatten_1 (None, 4, 4, 512) (None, 8192) 02 dense_3 (None, 8192) (None, 256) 20974083 dense_4 (None, 256) (None, 1) 257__________________________________________________________________________________Total Parameters : 16812353Total Trainable Parameters : 2097665Total No-Trainable Parameters : 14714688El nombre de matrius sobrepassa les capes perquè cada capa pot tenir una matriu de pesos www i un vector de bias bbb.
per a fer que es congelin les dades necessitem compilar el model i definim després els paràmetres per al generador.
from keras.preprocessing.image import ImageDataGeneratorfrom keras import modelsfrom keras import layersfrom keras import optimizerstrain_datagen = ImageDataGenerator(#rescale = 1./255, preprocessing_function=preprocess_input, rotation_range = 40, width_shift_range = 0.2, height_shift_range= 0.2, shear_range = 0.2, zoom_range = 0.2, horizontal_flip = True, fill_mode = 'constant', #'nearest') cval = 0)# La validación no se aumenta!test_datagen = ImageDataGenerator(#rescale=1./255) preprocessing_function=preprocess_input)train_generator = train_datagen.flow_from_directory( train_dir, # directorio con datos de entrenamiento target_size= (150, 150), # tamaño de la imágenes batch_size = 20, shuffle = True, class_mode = 'binary') # para clasificación binariavalidation_generator = test_datagen.flow_from_directory( validation_dir, target_size=(150, 150), batch_size=20, class_mode='binary')model.compile(loss='binary_crossentropy', optimizer=keras.optimizers.Nadam(lr=2e-5), #optimizers.RMSprop(lr=2e-5), metrics=)#model.reset_states()import timetstart = time.time()history = model.fit_generator(train_generator, steps_per_epoch = 100, epochs = 30, validation_data = validation_generator, validation_steps= 50, verbose = 2)print('seconds=', time.time()-tstart)Found 2000 images belonging to 2 classes.Found 1000 images belonging to 2 classes.Epoch 1/30 - 10s - loss: 1.9860 - acc: 0.7660 - val_loss: 0.7680 - val_acc: 0.9040Epoch 2/30 - 9s - loss: 0.9115 - acc: 0.8815 - val_loss: 0.5760 - val_acc: 0.9210...Epoch 30/30 - 9s - loss: 0.1956 - acc: 0.9640 - val_loss: 0.3213 - val_acc: 0.9660seconds= 281.5276675224304model.save('cats_and_dogs_small_3.h5')grafiquem de nou el comportament de les mètriques registrades durant el entre ment
import matplotlib.pyplot as pltacc = history.historyval_acc = history.historyloss = history.historyval_loss = history.historyepochs = range(len(acc))plt.plot(epochs, acc, 'bo', label='Entrenamiento acc')plt.plot(epochs, val_acc, 'b', label='Validación acc')plt.title('Accuracy - exactitud de entrenamiento y validación')plt.legend()plt.figure()plt.plot(epochs, loss, 'bo', label='Entrenamiento loss')plt.plot(epochs, val_loss, 'b', label='Validación loss')plt.title('Loss - función objetivo en entrenamiento y prueba')plt.legend()plt.show() 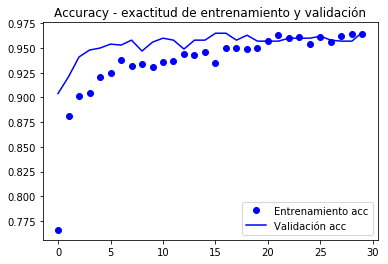
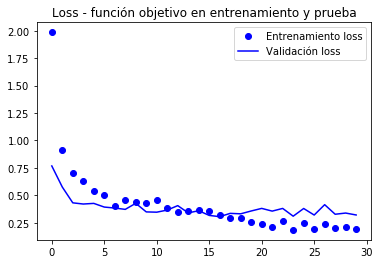
d’acord a l’autor de el llibre (Chollet), s’arriba a una exactitud de propera a l’96.5%.
Ajust fi
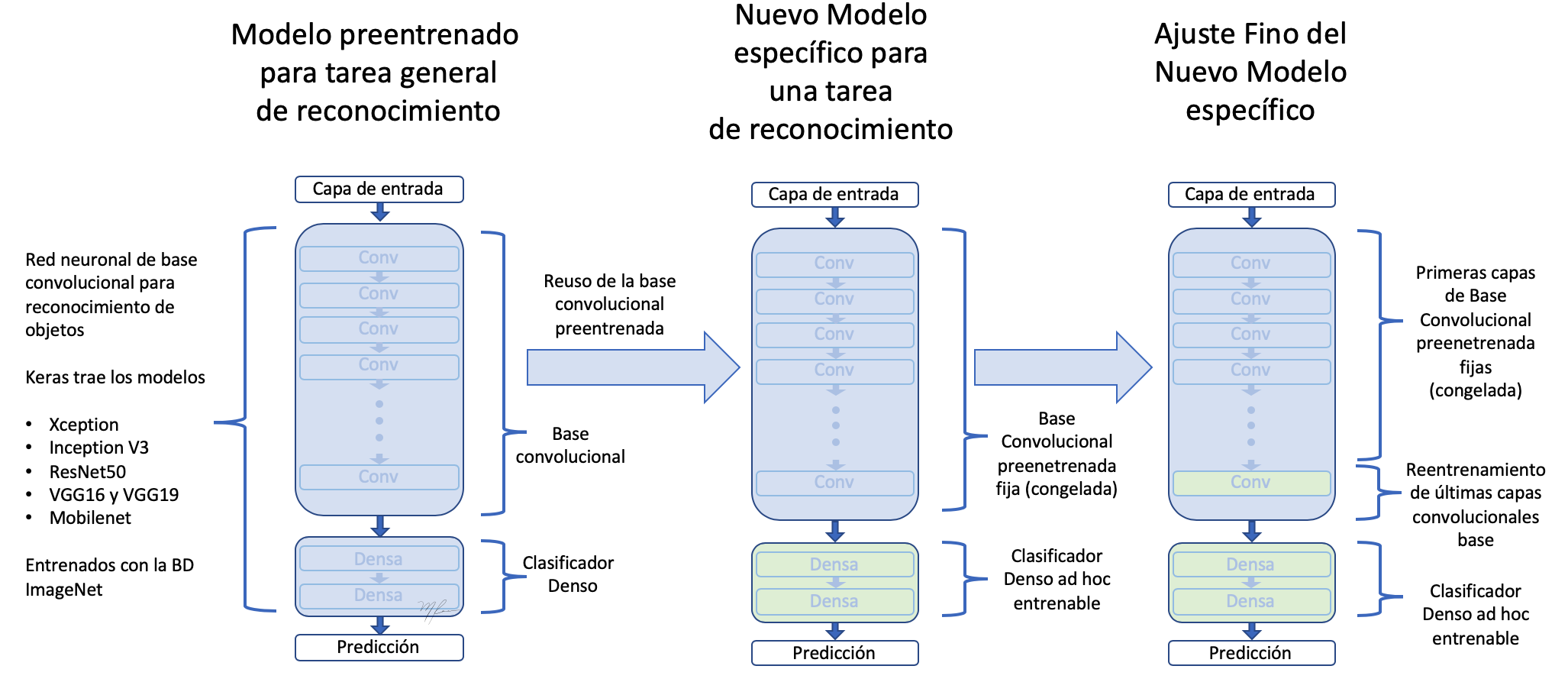
una altra estratègia àmpliament usada en reutilització de conocimeinto és el Ajust Fi (fine-tuning), el qual consite en què, un cop entrenada una capa classificadora amb base prenetrenada, descongelar les últimes capes de la base convolucional per permetre que els seus pesos s’adaptin millor a la capa classificadora. Aconseguint una millor integració entre la base (entrenada per a un problema diferent) i la classificació.
Els passos de l’entrenament fi són:
- Afegeix a la base convolucional general una etapa final de classificació.
- Congelar la base convolucional.
- Entrenar l’etapa classificadora.
- Descongelar les últimes capes de la base convolucional.
- Entrenar etapa classificadora i últimes capes de la convolucional juntes.
Partiedo de el model anteriors entrenat (passos 1,2, i 3) veiem que les capes a descongelar són les corresponents a l’bloque5.
Com a recordatori el resum de la convolucional és
resumen(conv_base)==================================================================================# Layer Name Layer Input Shape Layer Output Shape Parameters==================================================================================0 input_6 (None, 150, 150, 3) (None, 150, 150, 3) 01 block1_conv1 (None, 150, 150, 3) (None, 150, 150, 64) 17922 block1_conv2 (None, 150, 150, 64) (None, 150, 150, 64) 369283 block1_pool (None, 150, 150, 64) (None, 75, 75, 64) 04 block2_conv1 (None, 75, 75, 64) (None, 75, 75, 128) 738565 block2_conv2 (None, 75, 75, 128) (None, 75, 75, 128) 1475846 block2_pool (None, 75, 75, 128) (None, 37, 37, 128) 07 block3_conv1 (None, 37, 37, 128) (None, 37, 37, 256) 2951688 block3_conv2 (None, 37, 37, 256) (None, 37, 37, 256) 5900809 block3_conv3 (None, 37, 37, 256) (None, 37, 37, 256) 59008010 block3_pool (None, 37, 37, 256) (None, 18, 18, 256) 011 block4_conv1 (None, 18, 18, 256) (None, 18, 18, 512) 118016012 block4_conv2 (None, 18, 18, 512) (None, 18, 18, 512) 235980813 block4_conv3 (None, 18, 18, 512) (None, 18, 18, 512) 235980814 block4_pool (None, 18, 18, 512) (None, 9, 9, 512) 015 block5_conv1 (None, 9, 9, 512) (None, 9, 9, 512) 235980816 block5_conv2 (None, 9, 9, 512) (None, 9, 9, 512) 235980817 block5_conv3 (None, 9, 9, 512) (None, 9, 9, 512) 235980818 block5_pool (None, 9, 9, 512) (None, 4, 4, 512) 0__________________________________________________________________________________Total Parameters : 14714688Total Trainable Parameters : 14714688Total No-Trainable Parameters : 0 Farem l’ajust fi sobre les últimes tres capes convolucionals: block5_conv1, block5_conv2 i block5_conv3.
és important notar que les capes més primerenques codifiquen informació més general pel que no és convenient renetrenarlas si el propòsit és reutilitzar coneixement. Acabaríem sobreentrenando el model a nustras BD petita.
# Orden de las capas for layer in conv_base.layers: print(layer.name)input_6block1_conv1block1_conv2block1_poolblock2_conv1block2_conv2block2_poolblock3_conv1block3_conv2block3_conv3block3_poolblock4_conv1block4_conv2block4_conv3block4_poolblock5_conv1block5_conv2block5_conv3block5_poolconv_base.trainable = Trueset_trainable = Falsefor layer in conv_base.layers: if layer.name in : layer.trainable = True else: layer.trainable = False resumen(conv_base) ==================================================================================# Layer Name Layer Input Shape Layer Output Shape Parameters==================================================================================0 input_6 (None, 150, 150, 3) (None, 150, 150, 3) 01 block1_conv1 (None, 150, 150, 3) (None, 150, 150, 64) 17922 block1_conv2 (None, 150, 150, 64) (None, 150, 150, 64) 369283 block1_pool (None, 150, 150, 64) (None, 75, 75, 64) 04 block2_conv1 (None, 75, 75, 64) (None, 75, 75, 128) 738565 block2_conv2 (None, 75, 75, 128) (None, 75, 75, 128) 1475846 block2_pool (None, 75, 75, 128) (None, 37, 37, 128) 07 block3_conv1 (None, 37, 37, 128) (None, 37, 37, 256) 2951688 block3_conv2 (None, 37, 37, 256) (None, 37, 37, 256) 5900809 block3_conv3 (None, 37, 37, 256) (None, 37, 37, 256) 59008010 block3_pool (None, 37, 37, 256) (None, 18, 18, 256) 011 block4_conv1 (None, 18, 18, 256) (None, 18, 18, 512) 118016012 block4_conv2 (None, 18, 18, 512) (None, 18, 18, 512) 235980813 block4_conv3 (None, 18, 18, 512) (None, 18, 18, 512) 235980814 block4_pool (None, 18, 18, 512) (None, 9, 9, 512) 015 block5_conv1 (None, 9, 9, 512) (None, 9, 9, 512) 235980816 block5_conv2 (None, 9, 9, 512) (None, 9, 9, 512) 235980817 block5_conv3 (None, 9, 9, 512) (None, 9, 9, 512) 235980818 block5_pool (None, 9, 9, 512) (None, 4, 4, 512) 0__________________________________________________________________________________Total Parameters : 14714688Total Trainable Parameters : 7079424Total No-Trainable Parameters : 7635264 Note ara que la conv_base tenen paramteros entrenables i no entrenables.
Per a l’entrenament fi procedim a compilar el model amb una mida de pas petit per a evitar canvis grans en els pesos, ja que assumim estra prop de l’òptim i l’ajust no ha de ser molt gran.
model.compile(loss='binary_crossentropy', optimizer=optimizers.RMSprop(lr=1e-5), metrics=)history = model.fit_generator( train_generator, steps_per_epoch=100, epochs=100, validation_data=validation_generator, validation_steps=50)Epoch 1/100100/100 - 10s 104ms/step - loss: 0.1938 - acc: 0.9645 - val_loss: 0.2769 - val_acc: 0.9580Epoch 2/100100/100 - 9s 94ms/step - loss: 0.2239 - acc: 0.9635 - val_loss: 0.2606 - val_acc: 0.9650... Epoch 100/100100/100 - 10s 97ms/step - loss: 0.0269 - acc: 0.9960 - val_loss: 0.3666 - val_acc: 0.9620model.save('cats_and_dogs_small_4.h5')Gràfiques de les mètriques registrades durant l’entrenament
import matplotlib.pyplot as pltacc = history.historyval_acc = history.historyloss = history.historyval_loss = history.historyepochs = range(len(acc))plt.plot(epochs, acc, 'bo', label='Entrenamiento acc')plt.plot(epochs, val_acc, 'b', label='Validación acc')plt.title('Accuracy - exactitud de entrenamiento y validación')plt.legend()plt.figure()plt.plot(epochs, loss, 'bo', label='Entrenamiento loss')plt.plot(epochs, val_loss, 'b', label='Validación loss')plt.title('Loss - función objetivo en entrenamiento y prueba')plt.legend()plt.show() 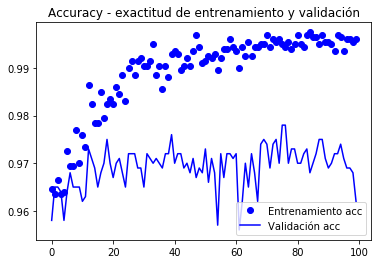
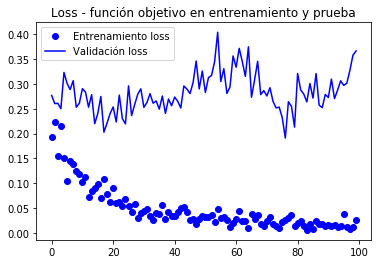
Atès que les corbes són molt sorolloses , és possible filtrar per apreciar millor la tendència mitjançant un filtre passa baixa, un podria intentar
s ~ i = Σk = 0nwksi-k \ titlla s_i = \ sum_ {k = 0} ^ n w_k s_ {ik} s ~ i = k = 0Σnwksi-k a on www són un pesos co n Σkwk = 1 \ sum_k w_k = 1Σkwk = 1; però requeriríem usar un filtre bastant ample (nnn gran) per eliminar soroll apropiadament, en comptes d’això tractem la versió recursiva (com en el llibre en què es basa aquestes notes)
s ~ i = αs ~ i -1+ (1-α) si \ titlla s_i = \ alpha \ titlla s_ {i-1} + (1- \ alpha) s_is ~ i = αs ~ i-1 + (1-α) si
Que fa servir la dada recent actualitzat amb un procediment similare. Aquests filtres recursius poden expressar-se com no recursius (substituint recursivament la dada actualitzat per la seva fórmula). L’avantatge de la forma recursiva és el compacte de es expressió d’actualització
def smooth_curve(points, factor=0.8): smoothed_points = for point in points: if smoothed_points: previous = smoothed_points smoothed_points.append(previous * factor + point * (1 - factor)) else: smoothed_points.append(point) return smoothed_pointsimport matplotlib.pyplot as pltacc = history.historyval_acc = history.historyloss = history.historyval_loss = history.historyepochs = range(len(acc))alpha = 0.9plt.plot(epochs, smooth_curve(acc, alpha), 'bo', label='Entrenamiento acc')plt.plot(epochs, smooth_curve(val_acc, alpha), 'b', label='Validación acc')plt.title('Accuracy - exactitud de entrenamiento y validación')plt.legend()plt.figure()plt.plot(epochs, smooth_curve(loss, alpha), 'bo', label='Entrenamiento loss')plt.plot(epochs, smooth_curve(val_loss,alpha), 'b', label='Validación loss')plt.title('Loss - función objetivo en entrenamiento y prueba')plt.legend()plt.show() 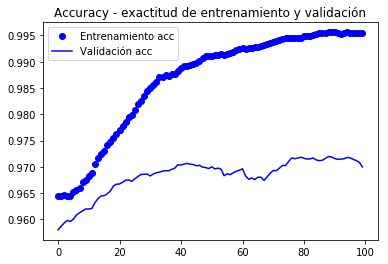
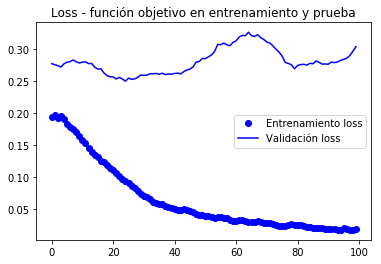
En aquestes corbes es pot apreciar millor la tendència, podem notar que va tenir una millora de l’entorn de l’1%.
En (Chollet, 2018) es fa l’observació que l’exactitud aquesta millorant tot i que la pèrdua no ho fa. Això es deu al fet que la pèrdua s’avalua mitjançant un procés de suma d’errors en el vector de sortida, alguna cosa com:
Σi∈epoch∥yi-i ^ i∥M \ sum_ {i \ in epoch} \ | y_i – \ hat y_i \ | _Mi∈epochΣ∥yi-i ^ i∥M
on assumim que yyy està en una codificació one-hot i M indica alguna mètrica.En canvi, l’exactitud es calcula mitjançant una suma errors de classificació:
Σi∈epoch1-δ (argmaxiyi-argmaxiy ^ i) \ sum_ {i \ in epoch} 1- \ delta (\ arg \ max_i y_i – \ arg \ max_i {\ hat y_i}) i∈epochΣ1-δ (argimaxyi-argimaxy ^ i)
Ara avaluem, finalment i per única vegada , el conjunt de prova:
test_generator = test_datagen.flow_from_directory( test_dir, target_size=(150, 150), batch_size=20, class_mode='binary')test_loss, test_acc = model.evaluate_generator(test_generator, steps=50)print('test acc:', test_acc)Found 1000 images belonging to 2 classes.test acc: 0.9669999933242798* Molt proper a l’97%
en la competència original de Kaggle, estaria entre els millors (top) resultats, i això que només fem servir 2000 dades d’entrenament vs. 20,000 en la competència de Kaggle.
Resum
-
Les xarxes convolucionals són el millor model de xarxes neuronals per tractar amb problemes de processament d’imatges i visió per ordinador .
-
la augmentació de dades permet evitar sobreajust en base de dades petites i incrementrar amb dades sintètiques la mida de la mostra d’entrenament
-
És possible utilitzar models preentrenados en l’etapa d’extracció de característiques per bregar amb bases de dades petites.
-
l’ajust fi permet millorar la interconección de l’etapa preentrenada amb la etapa classificadora, millorant l’acompliment general a un baix cost computacional.